视频识别与分类
本文将简要介绍一些从图像识别扩展到视频识别的技术。
问题背景
- 类似于 3D vision
,你所可以想象的图像方面的问题都可以扩展到视频当中。主要包括:
- Video Classification.
- Video captioning.
- Temporal Action Localization.
- Spatial-Temporal Detection.
切片分类
- 我们仍然从最基本的 Video Classification 谈起。一个显著的问题是视频的空间占用太大了,为了将其作为神经网络的输入,我们需要做非常激进的下采样,比方说仅保留 16 帧 112*112 像素的切片。在训练时,我们往往会对同一视频做多个切片;而在测试时,我们会考虑对目标取多个切片,并计算其均值。以下,假定我们要处理 T*3*H*W 的视频输入。
Single-Frame CNN
- 你可能会觉得提取视频中的单帧画面,逐帧通过 CNN 单独做 Image Classification ,最后对它们的概率做平均得到最终的结果是件很蠢的事,但实际上这种方式的效果意外的好,以至于截止2019年,Single-frame CNN 还经常作为此类问题的 baseline 。总的来说,这的确是一个非常值得一试的好选择。
Late/Early/Slow Fusion
要在 Single-Frame CNN 的基础上改进,我们考虑引入帧间联系。其一是在 Single-Frame CNN 的最后,将所有的 feature map 展平并拼接成单一向量(或者除 channel 以外的维做 Global Average Pooling),再通过 FCNN 以得到分类结果,称作 Late Fusion 。
若希望更早的建立初始帧之间的联系,可以考虑 Early Fusion ,即在一开始将所有帧按照 temporal 堆叠,再将该 3T*H*W 的张量输入一般的 2D CNN 。
实际上一个相对更好的看法是,我们保留 T*3*H*W 的输入格式,并直接对其做 3D convolution 。这种方法相比 Early Fusion 的好处是保留了 Temporal Invariant ,即可以使用单一 filter 提取周期性/不同时间点的特征。我们可以想象该方法中 temporal 上的联系是逐步建立的,因此将其称作 Slow fusion 。1
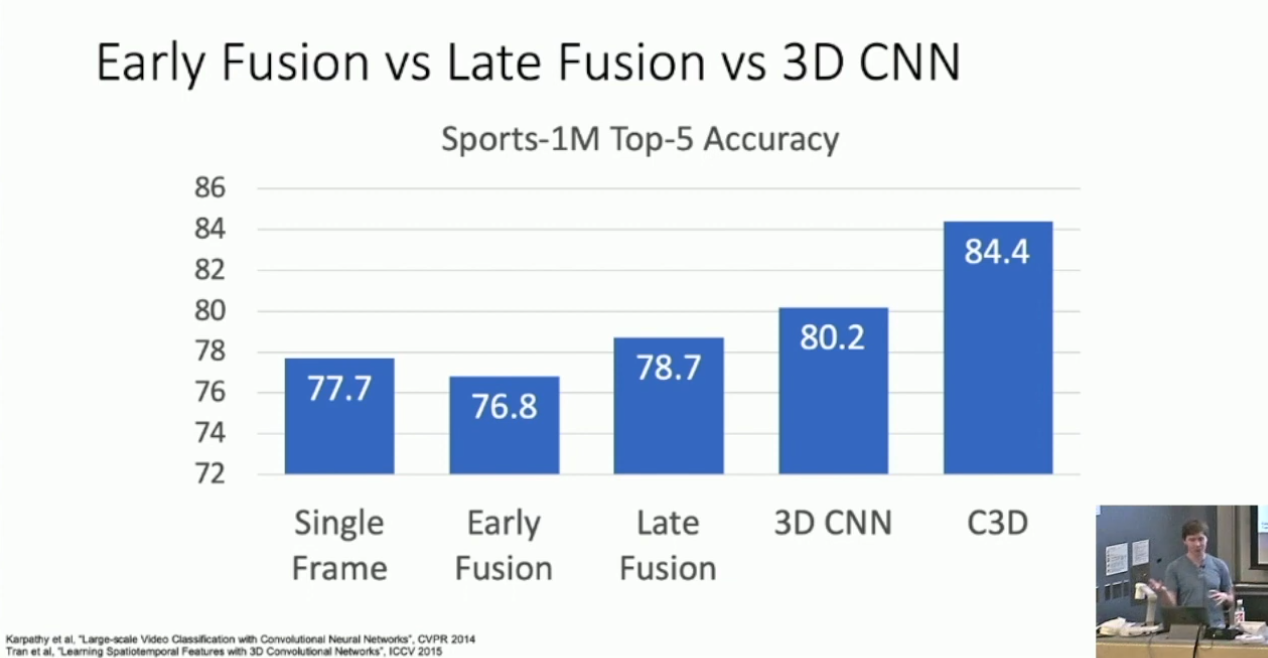
如果在数据集2上比较 Late/Early/Slow Fusion ,可以得到一些有趣的结果:

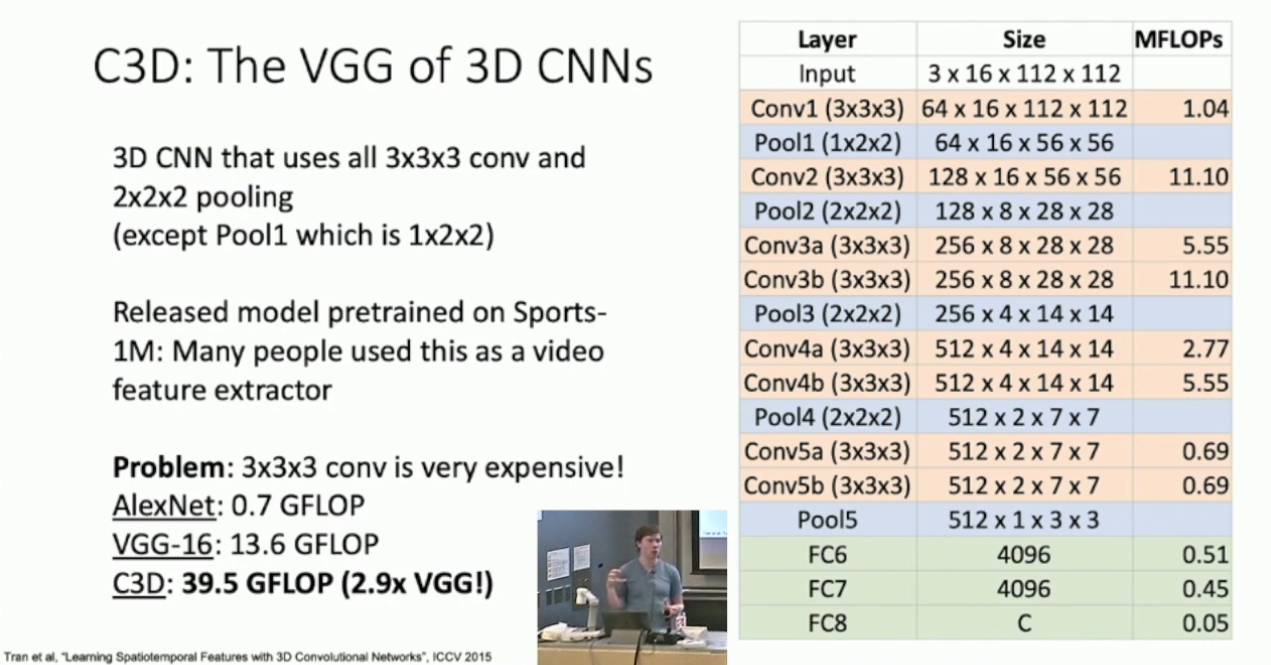
这说明 Single-Frame CNN 的效果确实非常不错。其中的 C3D 是一种构建 Slow Fusion 的方式,形似 VGG Net ,结构如下:
Optical Flow and Two-Stream Networks
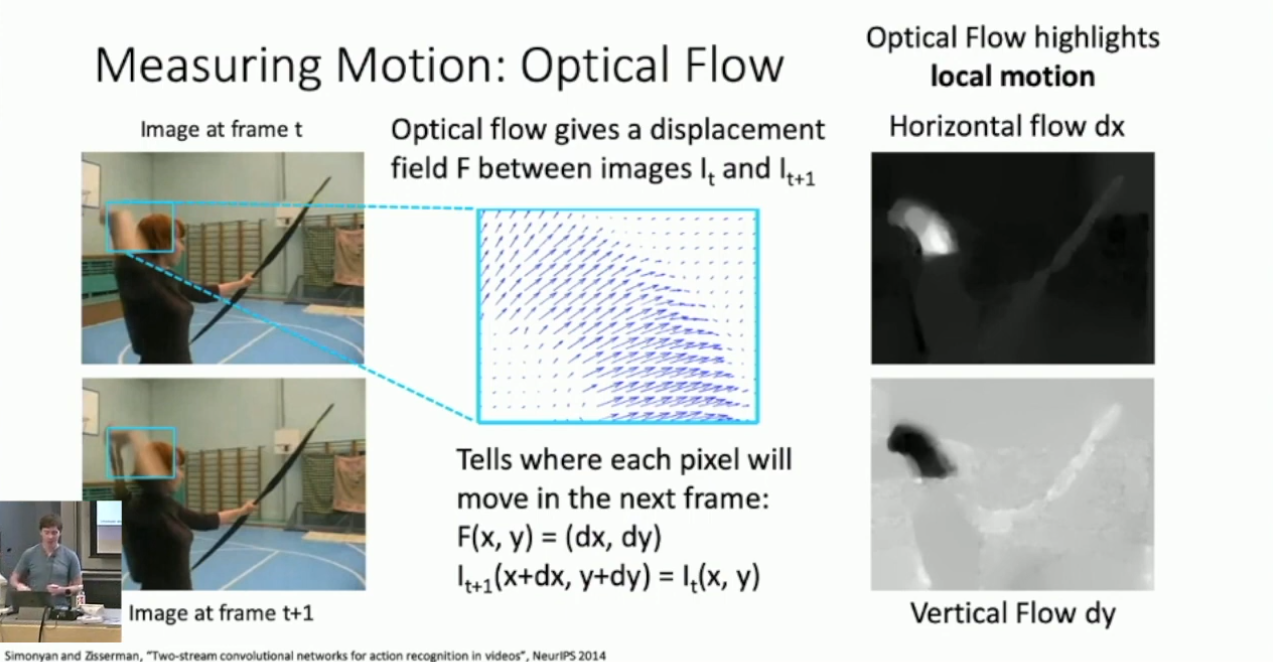
一个有趣的观点是人感知视频的一个重要方面是通过“动作”,我们希望将此概念同样引入到模型中,具体的方式则是 Optical Flow 。Optical Flow 描述的是像素在局部的帧间移动趋势,我们往往考虑垂直与水平两个方向:3
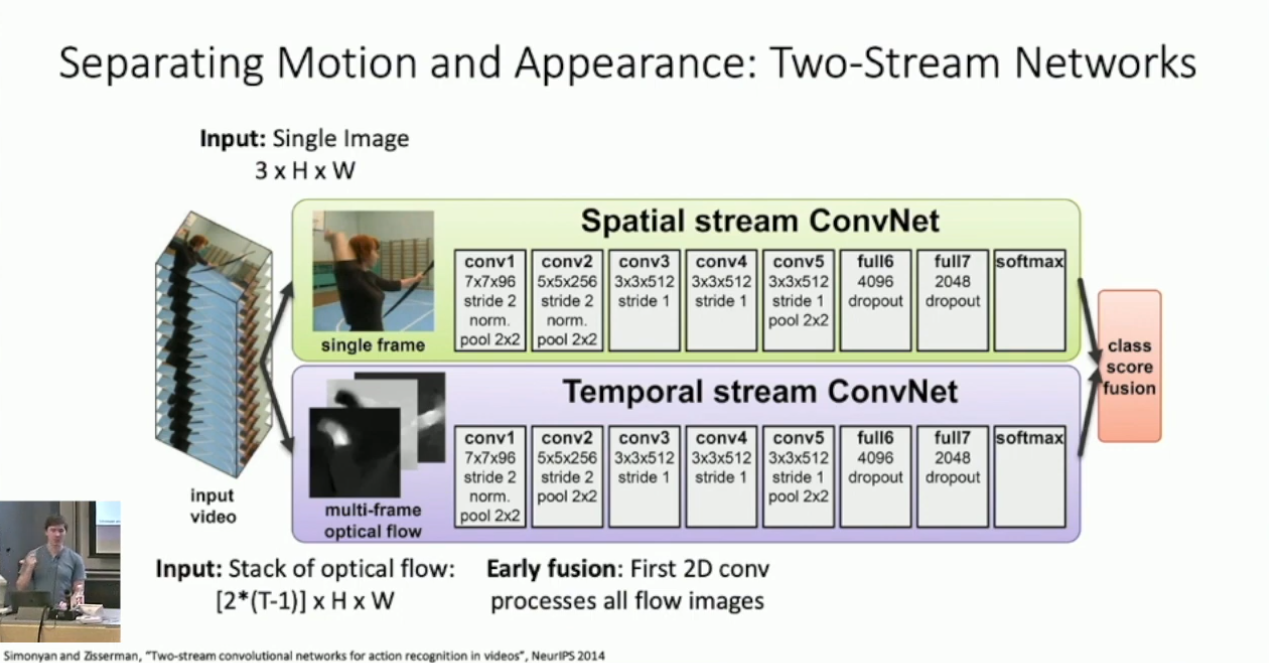
在此基础上,我们可以得到所谓的 2-stream network :
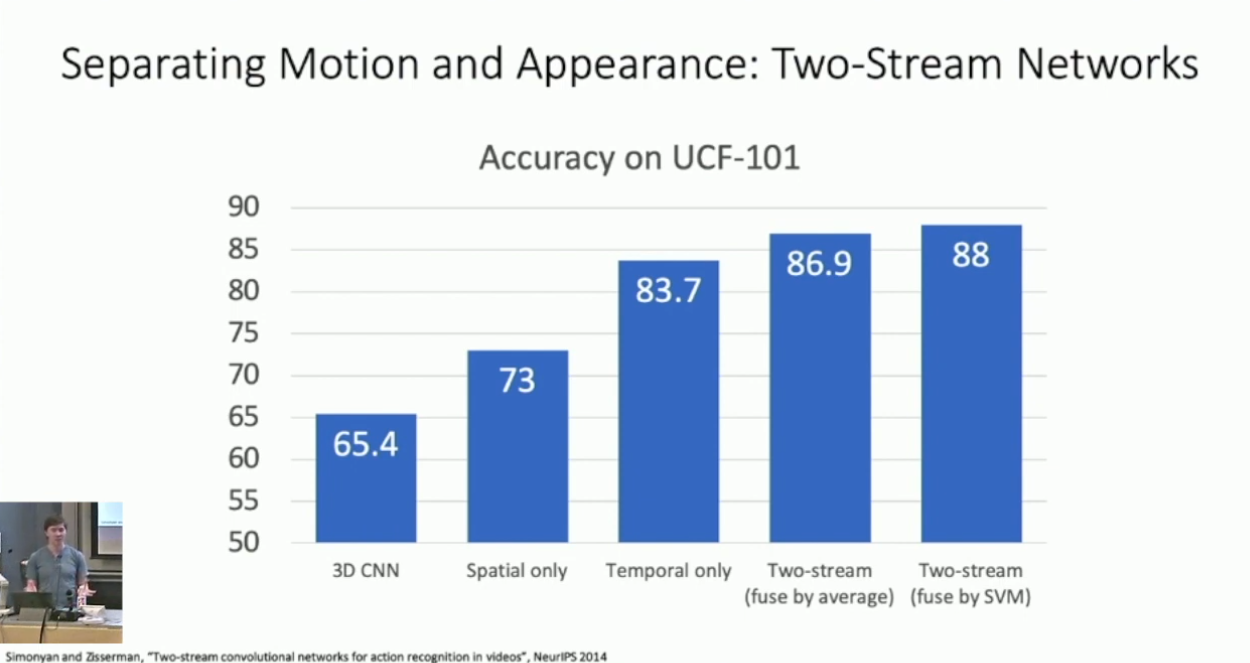
简单的说,对于 stream 1 ,我们提取切片中的单帧进行 Image Classification ;对于 stream 2 ,我们对于每一帧计算其 Optical Flow(这应是一个 2 channel 的张量),再对其做 Early Fusion 。在训练时我们分别训练 steam 1 & 2 ,而在推理时我们对它们的预测结果做平均。我们可以期待这样做融合了视频的外观和动作,而其确实也取得了不错的结果:4
长视频处理
我们无法直接使用 CNN 处理长视频,因为其开销太大。一个折衷的办法是,我们取长视频的若干时序切片,然后分别分析它们,最后使用某种序列处理方式,例如 RNN ,综合它们,以得到最后的结果。
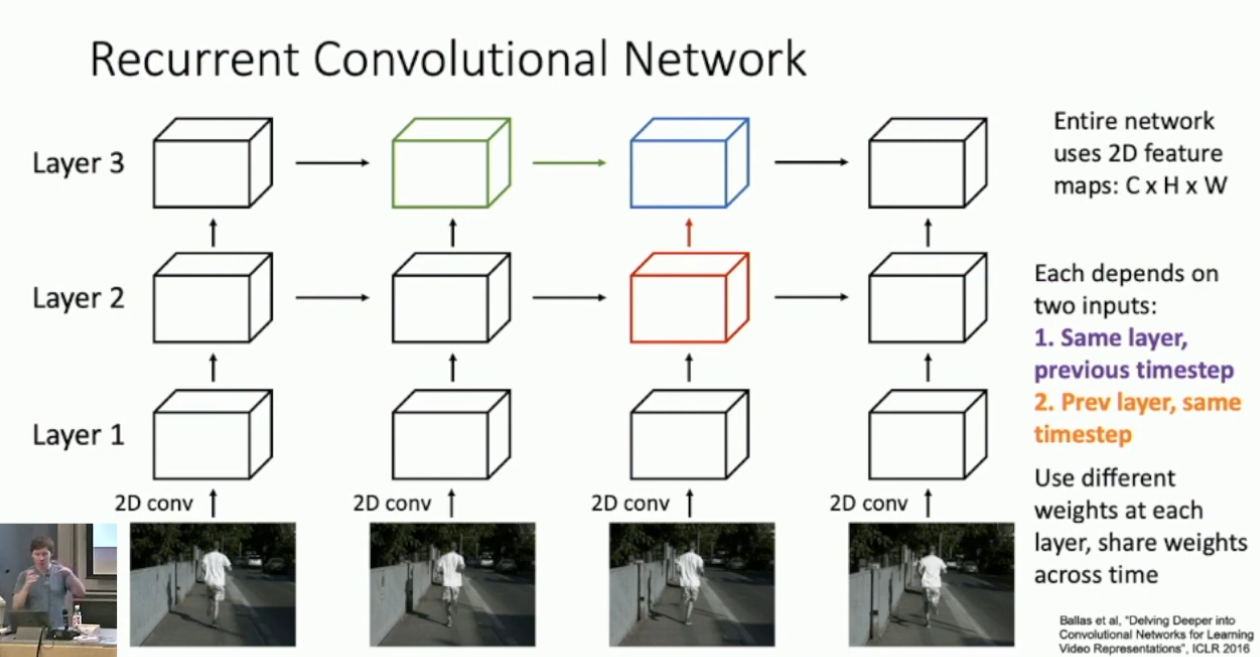
另外的一个观点是更深度的结合 CNN 和 RNN 。我们先前提到过 Multi-Layer RNN 这一技巧,在长视频处理中,我们考虑将 CNN 融入 Multi-Layer RNN ,称作 Recurrent Convolutional Network ,,大体结构如下:
简单的说,原先的 RNN ,例如 Vanilla RNN ,是对 feature vector 做操作;而现在我们的操作对象变成了更三维的张量,因此我们考虑转而做 2D convolution 。这样,原先的 RNN 架构,例如 GRU 和 LSTM ,都可以被无痛迁移到 RCN 当中。总的来说,RCN 融合了 CNN 的图像特征提取和 RNN 的序列处理,是一个好的结构,但主要的问题是 RCN 仍然存在时序依赖,无法被有效的并行化。
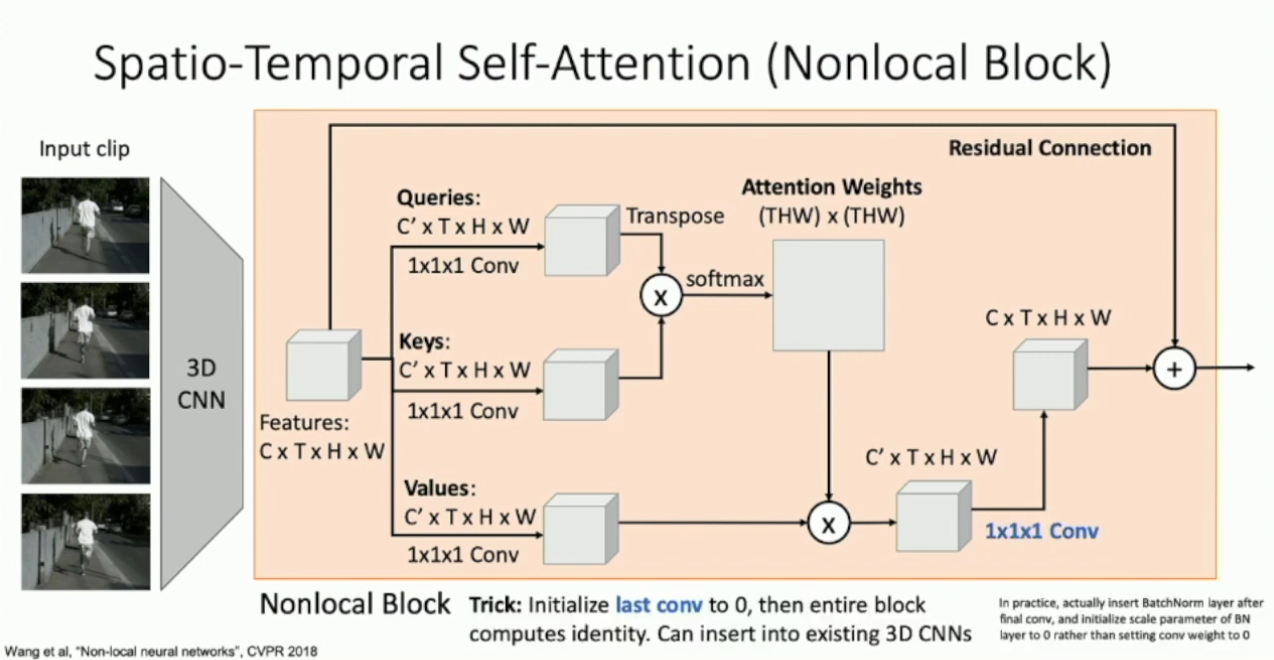
回忆在文本处理中,我们使用 Self Attention 替代了 RNN ,而前者是可以高度并行化的。在这里我们也可以做一样的操作。为此,我们可以设计出类似的 Video Self Attention 模块,即如下的 Nonlocal Block :5
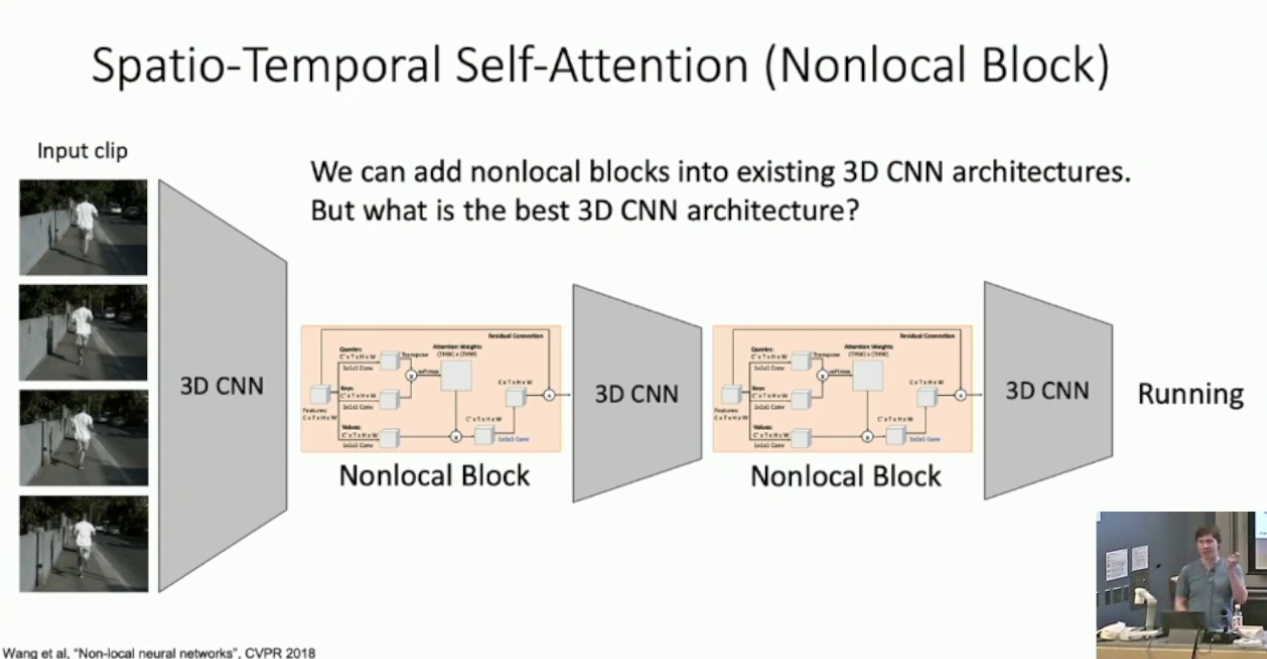
可以看出,Nonlocal block 同时做了时序上和帧内的 Self Attention 。将 Nonlocal Block 引入到 Slow Fusion 当中,我们就可以得到截止 2019 年的 SOTA 架构:
另外一个训练时的技巧是将最后的 1*1*1 卷积初始化为全
,从而令 Nonlocal Block 变成单位映射。然后我们直接将其插入预训练的模型,再进行 fine tuning 。
将图像模型用于视频
- 这其实是一个自然的想法,而对应的技术也是自然的:对于给定的图像模型,我们考虑其每一层卷积和池化的尺寸,为其增加一个时间维6,而时间维的参数则是原先参数的重复。这一方法没被称作 Inflating 2D networks to 3D(I3D)。有趣的是如上引入图像的先验以后,模型的表现其实比从头训练更好。另外我们也可以对 2-stream network 做相同的操作,分别为 stream 1 & 2 选择一个图像模型。
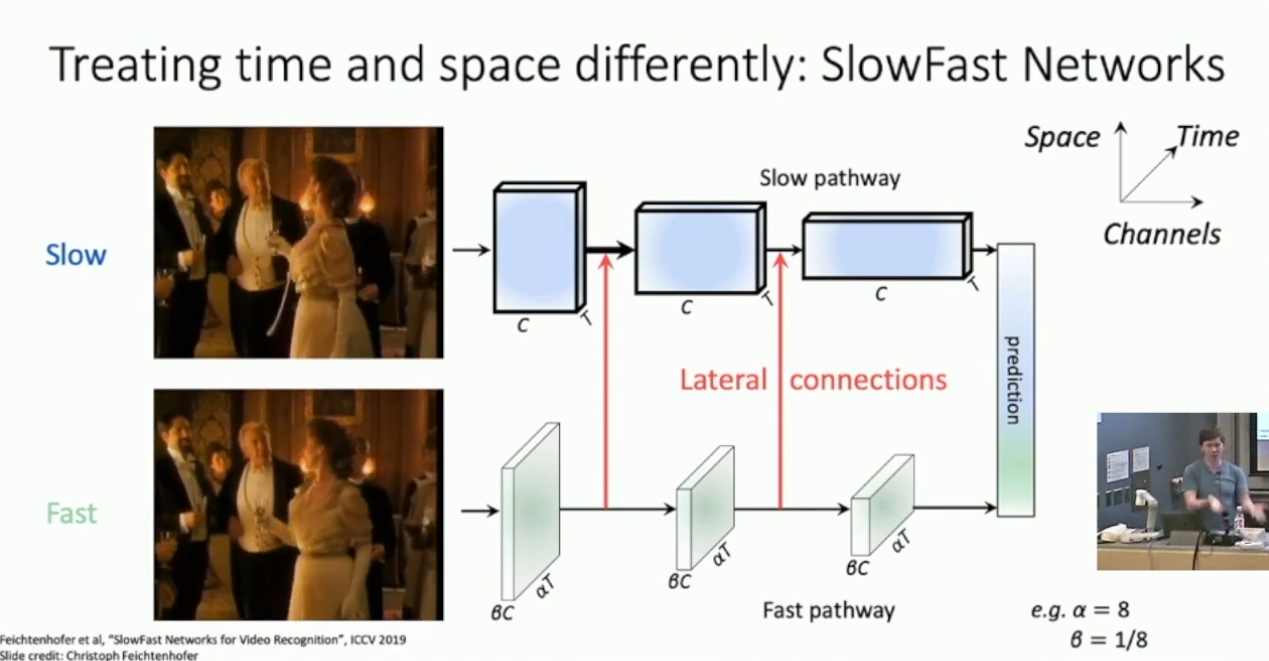
SlowFast Network
2-stream network 的缺陷是,其依赖于外部计算的 optical flow 。而 SlowFast Network 则改进了这一点,不同的是其并没有显式的拟合 optical flow ,而是令 stream 1 以高时间维处理低帧率的切片,stream 2 以低时间维处理高帧率的切片,并且加入 stream 2 到 stream 1 的横向信息传递,如下所示:
我们可以期待 stream 1 提取了视频的外观信息,而 stream 2 的类似 optical flow 的提取了动作信息。另外 SlowFast Network 也综合了先前介绍了另外一些技术,包括使用 I3D 构建 stream 1 & 2 7和引入 Nonlocal Block 。总的来说,SlowFast Network 是截止2019年的相当 SOTA 的方法。
3D convolution 本身的计算开销也会更大。另外 Slow Fusion 也可以像 2D CNN 一样对 filter 做可视化。实际上 Justin 也提到可以对广泛的视频模型做可视化,通过梯度上升生成最符合单一分类指标的视频。但我觉得这比较平凡,就不谈了。↩︎
此处选择了 Sports-1M ,包括了 Youtube 上截取的运动切片,分类粒度非常高。↩︎
具体的计算方式课上没有深入。↩︎
数据集是 UCF-101 。↩︎
Self Attention 的结构比较明晰,这里应该是不需要解释的。↩︎
具体怎么加课上没有细说。看起来一个不错的方法是添加与原先相同的大小。↩︎
以 ResNet50 为基础。↩︎
- 标题: 视频识别与分类
- 作者: RPChe_
- 创建于 : 2025-04-12 00:00:00
- 更新于 : 2025-04-15 00:43:23
- 链接: https://rpche-6626.github.io/2025/04/12/DL/VDO/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
