物件侦测与语义分割
本文简要介绍了用于 Object Detection 的 Region Proposal 以及 R-CNN 。
问题背景
- Image Classification 其实是一个相对简单且基础的任务。现在我们考虑一些更难的任务,包括 Semantic Segmentation 、Object Detection 以及 Instance Segmentation 。本文的主线是 Object Detection ,其目标是,给定一张图片以及一些标签,找到图片里在标签中出现的物件,并使用方框标记它们。
算法描述
- 以下我们将简要介绍用于 Object Detection 的 Region Proposal 和 R-CNN 。另外还有一些没什么前途的技术,我们就略过不谈了。
Region Proposal
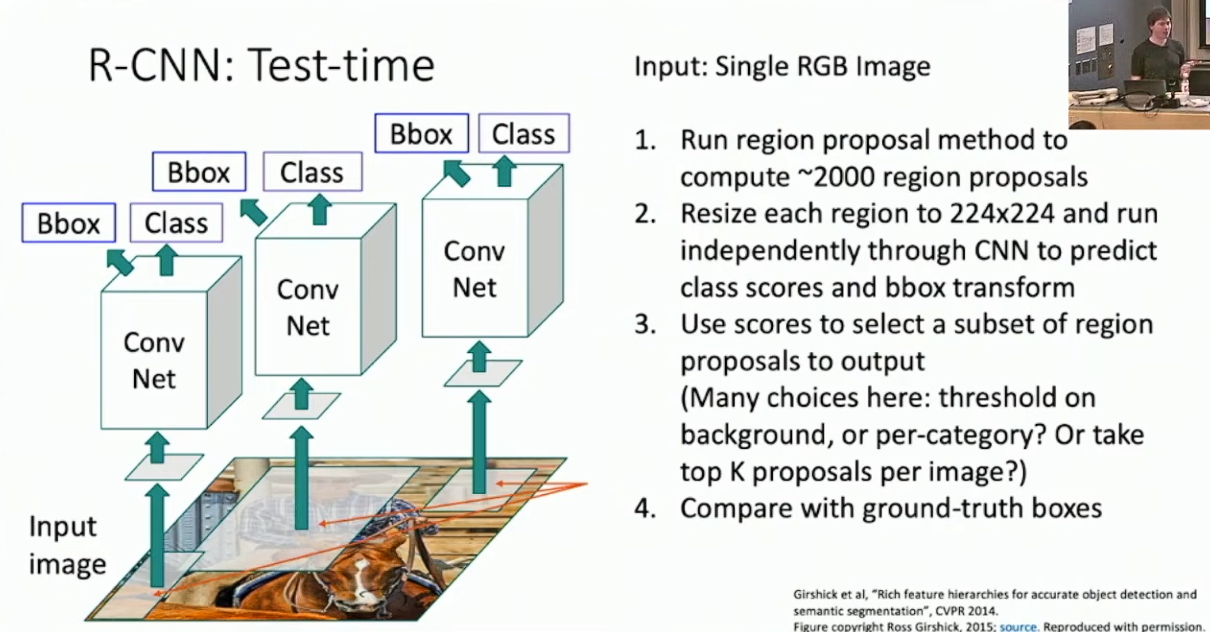
不妨想想直觉上我们要如何做 Object Detection 。先前的 CNN 只能针对单一图片做分类,一个自然的想法是我们希望通过某种方式找到一些可能包含标签物件的切片1,然后使用 CNN 来判别它们、并调整切片的位置来得到最终的输出。推荐切片的过程被称作 Region Proposal ,而模型整体则被称作 Region based CNN 。
早先 Region Proposal 的较为主流的实现方式是 Selective search 。Selective search 是一种运行在 CPU 上的启发式算法,其对于给定的图片推荐 2000 个切片(称作 Regions of Interest ,RoI),以极高的概率包含了所有的标签物件。
对于所有的 RoI ,我们将会把它们缩放为固定的分辨率,并输入一个 CNN 以得到分类结果。一个问题是 RoI 的位置不一定是合适的,所以我们还需要为 CNN 加入调整 RoI 位置的功能。具体的,我们通过 4 个参数
来描述 RoI ,分别代表其中心坐标以及其高宽。而 CNN 要预测的对象则是这 4 个参数的变动量2 ,得到的新参数为: 这样参数化的好处主要是,其和绝对位置无关,而对相对位置操作,再加上一开始的缩放,就具备较好的 Scale Invariant 。最后的损失函数则是 CNN 的 softmax loss 和 RoI 位置参数损失的加权和,称作 Multi-task loss 。这样,我们就可以搭建最基本的 R-CNN 了,如下图所示: 
首先,我们需要评估两个切片在空间上的相似度,以确定它们是不是在描述同一个物件,主流的方法是 Intersection over Union(IoU)。具体的,对于两个切片,我们先计算包含它们两者的最小矩形的面积(Union),再计算它们的交的面积(Intersection),然后我们以 Intersection 与 Union 的比作为评价指标。一般来说,当 IoU 大于 0.5 ,我们认为结果可接受的;当 IoU 大于 0.7 ,结果是相当好的;当 IoU 大于 0.9 ,结果几乎是完美的。
现在我们考虑如何设计训练 R-CNN 时的损失函数,这一点其实是类似于 Image Classification 的。具体的,对于 Region Preoposal 得到的切片,我们计算其与所有 groud truth box 的 IoU ,并令切片对应其中的最高者。若该 IoU 高于某一阈值,我们就认为该切片是好的;反过来,若 IoU 低于另一阈值,该切片就是坏的。3接下来,我们添加一类背景标签,用于描述坏切片。我们希望训练 CNN ,使其可以将所有好切片辨认为对应的 groud truth box ,并且将所有的坏切片辨认为背景。而具体的损失函数就设计为标签分类的 softmax loss ,再加上预测好切片的位置参数时的回归损失4。
特别的,可能有切片无法被判定为好和坏,我们认为这些切片可能会迷惑模型,所以它们是不参与训练的。
预测结果评估
不同于 Image Classification ,如何评估 R-CNN 在测试集上的表现是一件麻烦的事情。不妨先考虑如何对 R-CNN 的输出去重5,即可能存在不同的切片描述了同一物件,我们只保留预测得分最高的那个。具体的,对于每一个标签,我们选择得分最高的切片,并去除那些和这一切片的 IoU 高于某一阈值(例如 0.7)的切片,然后重复这一过程。这一算法被称作 Non-max Suppression(NMS)。当然,NMS 总体来说还是相当粗劣的,对于物件非常密集的图片,其表现并不好。6
最后,我们考虑评估去重以后的输出的优劣。为此我们有一套较为复杂的流程,称作 Mean Average Precision(mAP)。具体的,对于每一个标签,我们将所有的切片按照得分从大到小排序。然后我们按顺序考虑每一个切片:若该切片以高于某一阈值的 IoU 匹配了某一答案切片7,那么我们将该答案切片从候选答案中去除。然后,对于切片序列的每一个前缀,我们计算两个指标,分别是准确率(Precision),即匹配的切片数比该前缀的总数;以及召回率(Recall),即匹配的答案切片数比其总数。然后我们将所有前缀的 Recall 和 Precision 分别作为横纵坐标,在二维平面
的区域中作出这些点,并将它们依次连接。鉴于 Recall 是不减的,我们可以计算该曲线与 轴围成图形的面积,称作 Average Precision ,并将其作为该类标签的优劣指标。 显然 Average Precision 是在 0~1 之间的。Precision 和 Recall 分别评价了输出的不同维度的优劣:在医疗诊断时,我们可能希望 Precision 更高;而在自动驾驶上,我们可能希望 Recall 更高。而 Average Precision 则在某种程度上综合了这两类指标。
最后,我们再令 mean Average Precision 为所有标签的 Average Precision 的均值,这就给出了最终的评估指标。鉴于匹配判定受 IoU 阈值影响很大,我们有时也会考虑对不同的阈值计算 mAP ,再取均值。
特别的,请注意结果评估和损失函数是两码事,请不要混淆。
Fast R-CNN
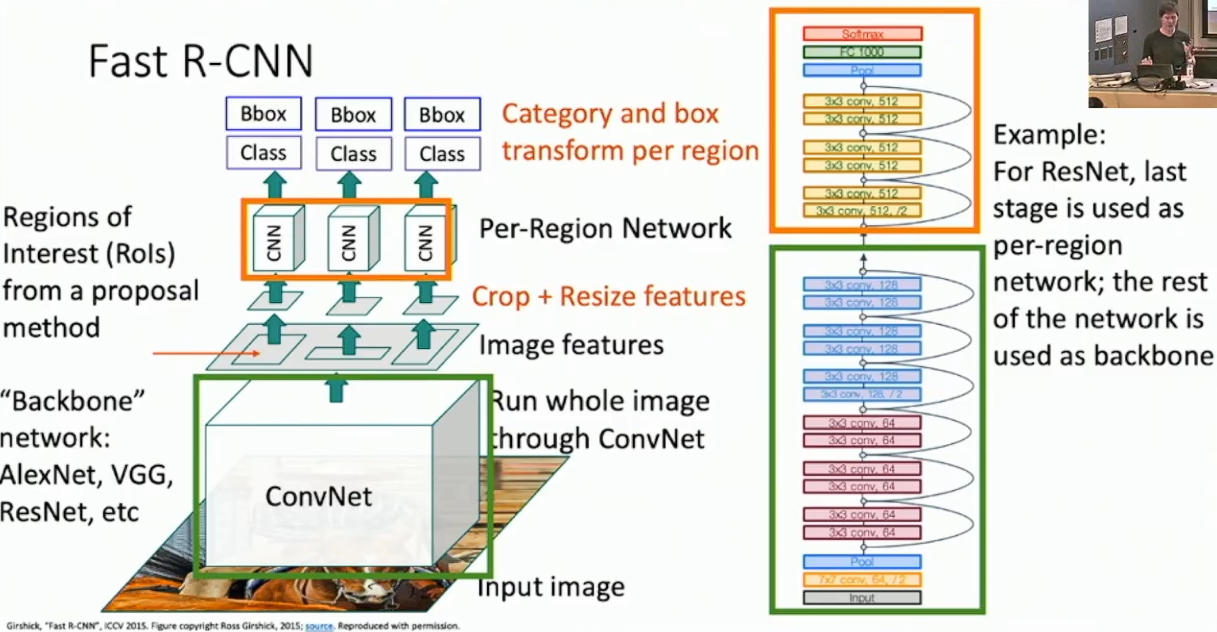
先前的 R-CNN 太慢了,难以在终端中实时运行。而其时间复杂度的主要来自多次运行完整的 CNN ,因此我们考虑将 CNN 的运行进行合并。具体的,我们先让原图通过一个较大的 CNN(称作 Backbone Network)以进行特征提取,然后对于每一个 Region Proposal 得到的切片,我们将其投射到 Backbone Network 最后得到的 feature map 上,然后对投影8进行剪切,再将其分别输入另一个较小的网络(称作 Per-Region Network)以进行最后的预测。
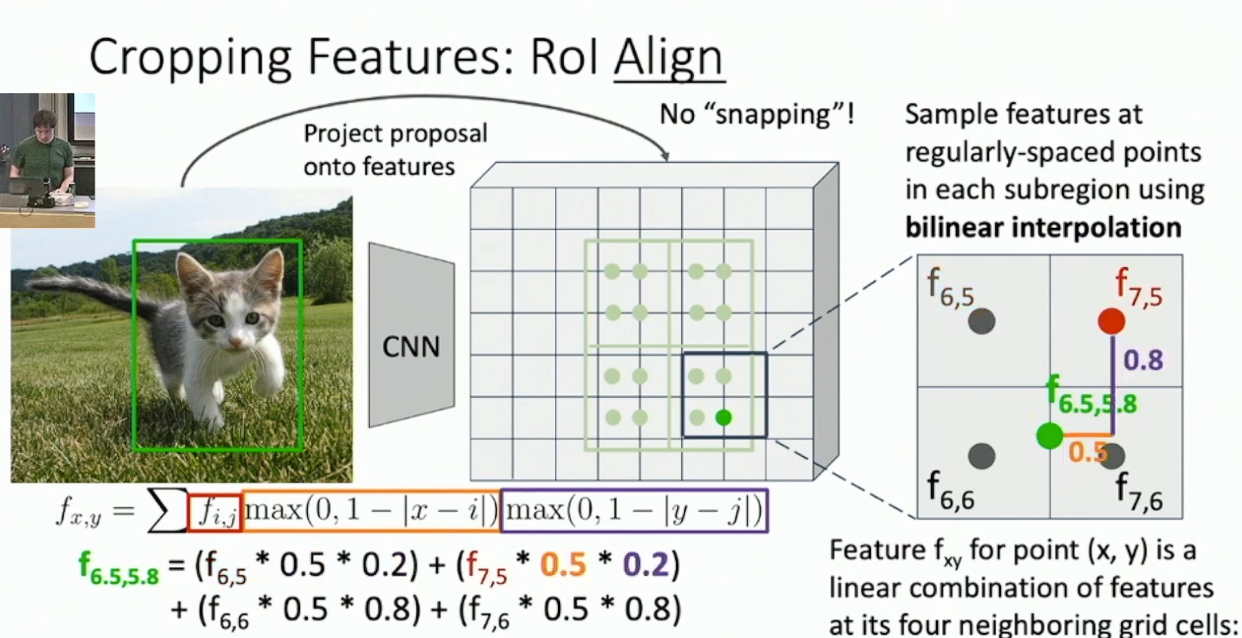
上述算法主要的问题是,我们要如何将原先的切片投射到 feature map 上,因为这些切片不一定可以对齐 feature map 的网格。一个简单的方式,被称作 Region of Interest Pool ,大概是强行进行切片到 feature map 的对齐,然后按照 PRN 的输入大小对投影进行尽量均匀的切分,再对每一块做 max pool 。另一个更好的方式被称作 RoI Align ,过程是先按照 PRN 的输入大小对切片进行均匀的切分,然后对于每一块,我们选定一些采样点。这些点的坐标不一定是整数,即不一定可以对齐 feature map ,所以我们需要采取名为 bilinear inperpolation 的方式,即选定距离该采样点最近的四个 feature vector ,按照距离加权计算它们的均值,作为该点的采样。最后我们再对于每一块做 max pool ,以得到 PRN 的输入。示例如下:
我们期待 RoI Align 可以在一定程度上解决无法对齐和采样不均匀的问题,并且优化梯度的传播。
另外,Backbone Network 和 PRN 一般也来自于预训练的模型。比方说 AlexNet ,我们会将全部的卷积层用作 Backbone Network ,将其余的 FCNN 用作 PRN ;或者 ResNet ,我们会将绝大部分网络用作 Backbone Network ,将最后的几个 Residual Block 用作 PRN 。
下图展示了 Fast R-CNN 的结构:
特别的,Fast R-CNN 的损失函数和原先基本一致,除了判定好坏切片的过程必须在线进行。
Faster R-CNN
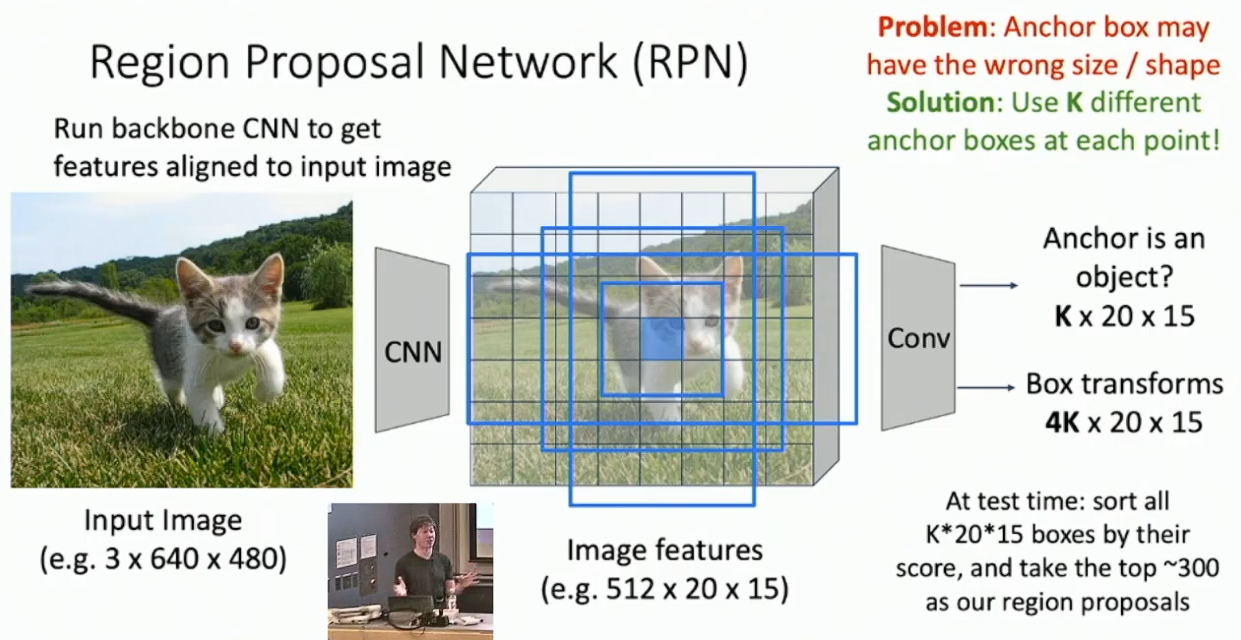
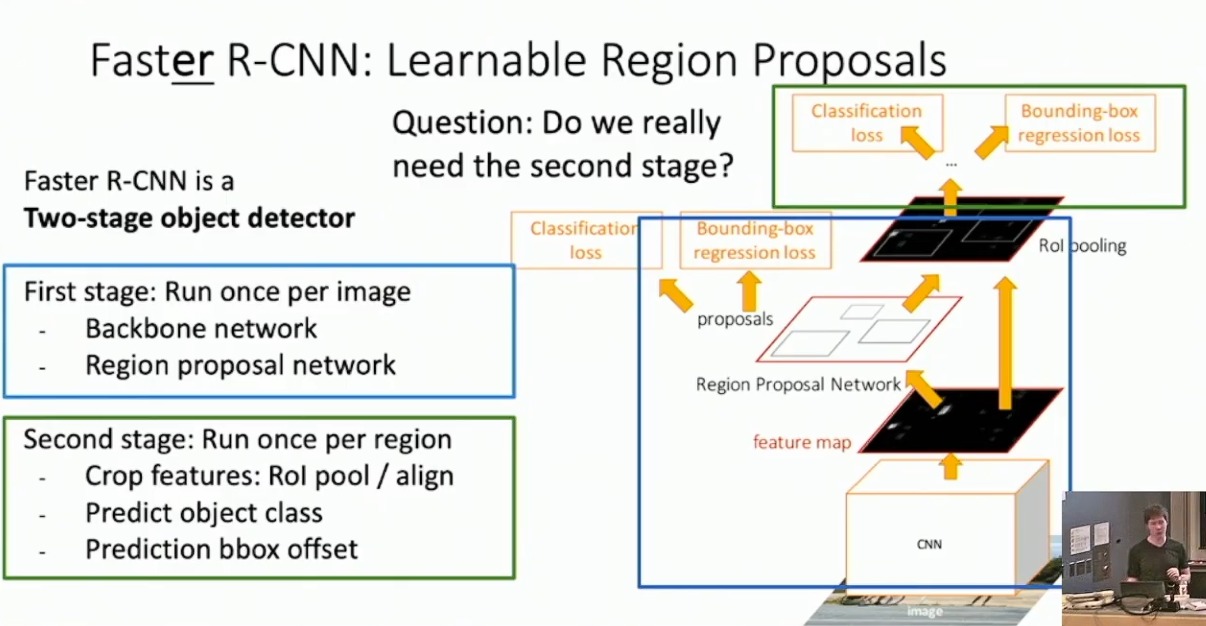
Fast R-CNN 已经显著的快于 R-CNN 了,现在的时间复杂度瓶颈在于 CPU 上运行的 Selective Search 。我们考虑同样使用神经网络来执行 Region Proposal 。具体的,我们考虑在 Backbone Network 得到的 feature map 上加入一个较小的神经网络,称作 Region Proposal Network 。对于 feature map 的每一个位置,我们在此处嵌入若干个不同大小的 anchor box 9,并使用 RPN 做 3 分类,以预测每一个 anchor box 是好的、坏的、或者中性的,并预测非中性物件的位置参数。
当获得 RPN 的输出以后,我们执行与 Fast R-CNN 完全相同的步骤。特别的,我们可能要使用与之前的结果评估相似的方式来设计 RPN 的输出的损失函数。10
One Stage Method
Faster R-CNN 被称作 Two Stage Method ,我们将到 RPN 为止的部分视作 Stage 1 ,将 PRN 视作 Stage 2 。其实一个自然的观点是,我们能不能直接拿 RPN 来预测最终的分类结果,而答案是可以。One stage method 和 Faster R-CNN 的结构差别不大,大概只需将 RPN 输出改成对每个标签都预测就行。一个细节是对于每个位置,每个标签,每个 anchor box 都分别预测偏移量,结果会相对好一点。
下图展示了 Faster R-CNN 的结构,标注了 First Stage 和 Second Stage :
不同模型的比较
截止 2019 年,Object Detection 似乎还在迅速发展。我们在这里无意详述模型之间的性能比较,你可以通过下面这张图直观的感受到:
Justin 的另一个建议是,最好不要试着自己写 Object Detector ,因为它们实在是太复杂了,有很多的超参数需要调整。如果你主要的精力并不在此处,更好的选择是直接找一个现成的模型。

其它识别任务
- 以下我们将简要介绍一部分识别类任务。这些任务比起 Object Detection 显著简单,或是以 Object Detection 为基础。
Semantic Segmentation
对于给定的图片,我们希望对于每一个像素点标记其类别。
先考虑一个简单的模型,即 Fully Convolutional Network 。其每一次只做保持尺寸的卷积,最后得到 C 层 feature map ,其中 C 恰为标签种类。对于每一个位置的 feature vector ,其第
维的值就代表该位置的像素分类为标签 的指标,最后的损失函数为每个像素的 softmax loss 。 FCN 太慢了,所以我们考虑先做下采样,最后再上采样回来。那么问题就在于我们要如何进行上采样。可选的技术如下列出:
Bed of Nails Unpooling. 每个位置扩大为一个方阵,其左上取原值,其余位置取
。 似乎不是一个好选择。
Nearst Neighbor Unpooling. 每个位置扩大为一个方阵,其所有位置均取原值。
Bilinear Interpolation. 在原 feature map 上均匀放置采样点,使用 bilinear interpolation 生成输出。
Bicubic Interpolation. 技术问题,无意深入,自行查阅。
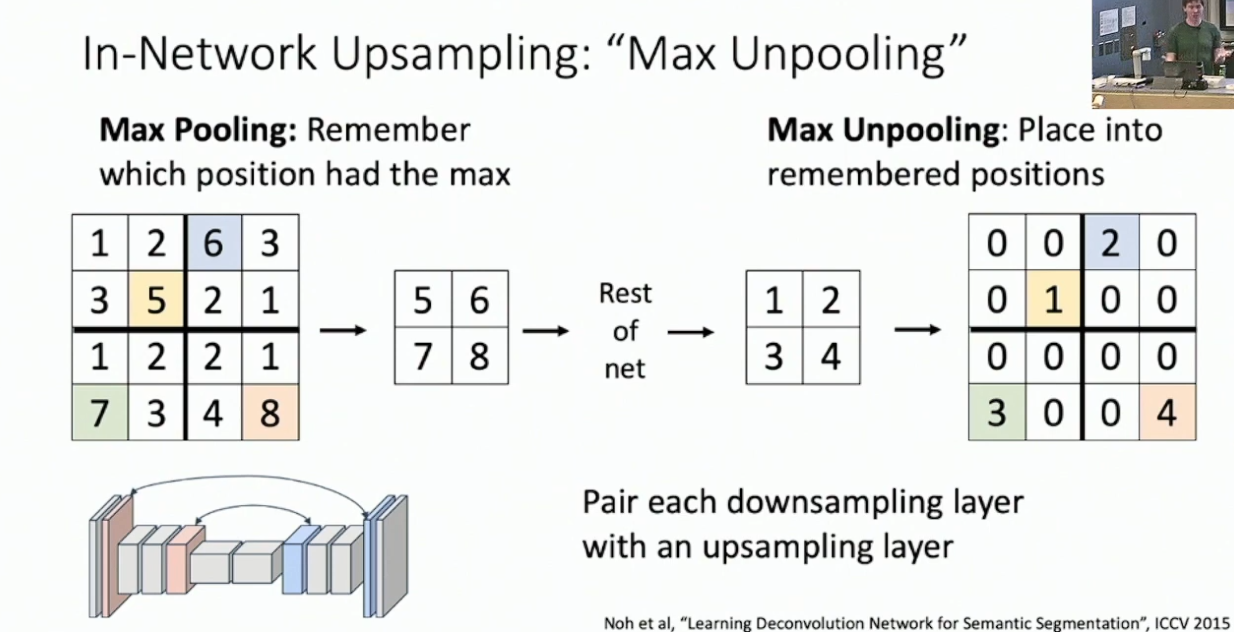
Max Unpooling. 其要求上采样的过程与下采样对应,从而 max pool 对应的上采样就是每个位置扩大到原先的尺寸,并且只有 max pool 贡献的位置非 0 。
而 average pooling 对应上采样一般是 Nearst Neighbor Unpooling 或者 Bilinear Interpolation 之类的。11
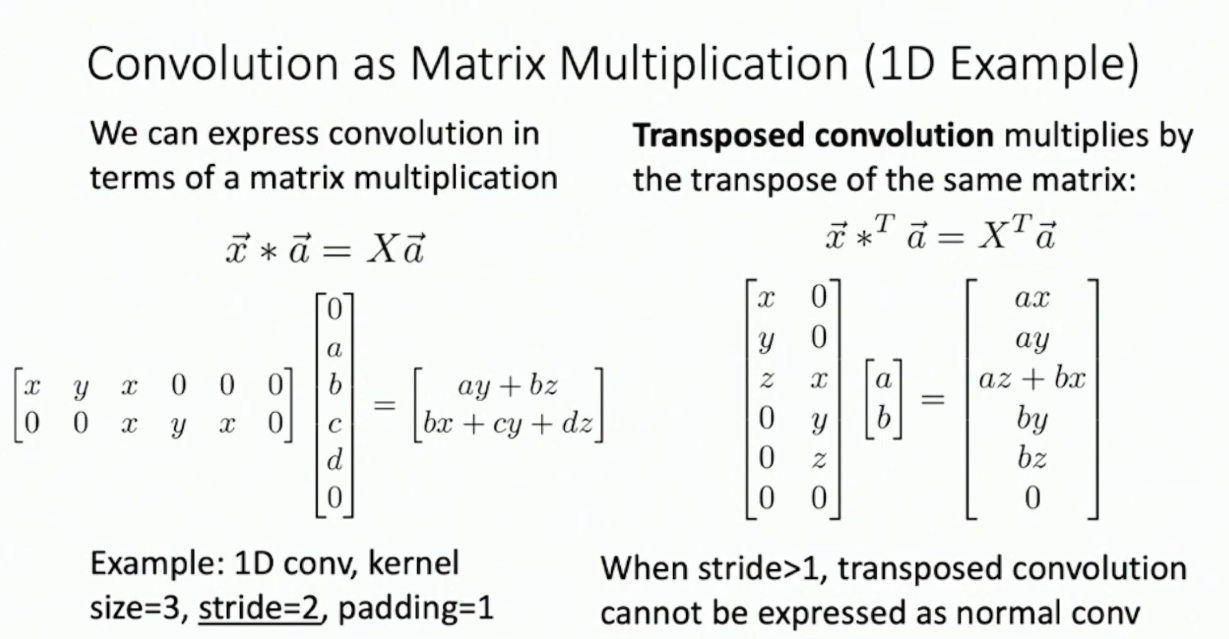
Transposed Convolution. 通过设定 stride 大小,卷积是可以做下采样的。不妨考虑卷积能不能做上采样——严格的说,不行,但是有类似的技术可以做到,这就是 Transposed Convolution 。Transposed Convolution 基本是把 Convolution 按原先的方式反着做了一遍。至于为什么叫 Transposed ,考虑以下的一维形式:
我们把卷积的矩阵转置了。其实 Transposed Convolution 的另一意义是,其形式上就是卷积层的反向传播。12
Instance Segmentation
- 对于给定的图片,我们希望分割出其中的每一个标签物件。
- 这个问题看上去很像先做 Object Detection ,再在切片里面做 Semantic Segmentation ,而实际上我们也是这样操作的。
- 唉其它细节等我上手 Object Detection 再说吧。问题太多了。
指图片的一部分。↩︎
其实参数化方式很多,这种比较常用。 ## 损失函数设计↩︎
如果你使用类似 Selective Search 的非学习方式,这些过程可以离线处理。↩︎
例如使用
loss 。↩︎ 我们往往会选择一部分切片输出,选择方式则比较多。↩︎
截止 2019 年似乎还没有什么特别好的办法。↩︎
答案大概是需要预先标注出来的。答案切片就是 Groad truch box 。↩︎
即切片投射到 feature map 上对应的区域。↩︎
即固定大小的切片。有一个问题是每一个位置的 feature vector 应该都有其视野,所以此处的 anchor box 应该不能比其更大。但考虑到 RPN 之前的 Backbone network 已经对原图进行了特征提取,此时的每一个 feature vector 应该都具备较大的视野,所以 anchor box 大过视野的情况可能并不用考虑。↩︎
感觉有点奇怪。我没搞懂这里具体是要干什么。等我上手以后再详说。↩︎
这样做的好处是保持了网络的对齐。但理论上到底有什么保证 Justin 也没详说。↩︎
不知道有什么理论上的深刻之处。↩︎
- 标题: 物件侦测与语义分割
- 作者: RPChe_
- 创建于 : 2025-03-26 00:00:00
- 更新于 : 2025-04-15 00:51:19
- 链接: https://rpche-6626.github.io/2025/03/26/DL/OD/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。

