卷积神经网络的可视化与可解释性
CNN 的中间结果可视化技术原来还可以拿来干这些事情。
问题背景
- 先前我们已经简要介绍了 CNN 的结构,现在我们希望可以找到好的方式来可视化 CNN 的中间结果,以提供可解释性。
可视化技术
- 我们先简要的介绍一些可视化技术
画出 CNN 的第一层 filter
- CNN 的第一层 filter 必然是 3channel 的,这使得我们可以使用三通道 RGB
的方式作出其图像。如果你实际操作过的话,这些 filter
大致是某种斑点、色块和不同指向的边缘。可以认为 filter
实际上是在提取原图中的这些信息,因为我们知道
内积可以被视作某种对相似度的度量1。但是这些图像似乎并不具备较强的可解释性,而且其余层的 filter 也不一定是 3channel 的。我们可以试着做出其余 filter 的灰度图像,但效果并不好。
对 CNN 最后的特征向量做降维
- 我们之前在迁移学习中就提到过,可以认为 CNN
在最后的分类之前得到的特征向量编码了图像的信息。如果我们对这些这些向量做
KNN
,可以发现同一类别的图像很大程度上是相邻的。为了将这个现象可视化,我们考虑将
中的向量降维到 上,可用的算法包括 PCA 和 t-SNE 。可以发现,降维之后同一类别的特征向量确实几乎是聚集在一起的。
画出 CNN 中间层的 feature map
- 我们也可以取某一中间层,画出其所有的 feature map 的灰度图像。我们可以期待,存在一部分的 feature map ,它们对输入图像有较强的反应,并且表达了输入图像的某种特征。另一个细节是,大部分的 feature map 都不会对输入起任何反应,这大概是因为 ReLU 把所有负值都改成了 0 。
输入图像对某一神经元的影响
- 考察某一层中某一个 feature map 上某一个神经元对输入的反应,我们挑出造成反应最显著的一部分。我们可以期待,这些图像2很大程度上具有相似的特征。而当考察的神经元的深度加深,其视野会更大,也会越发关注图像整体。
显著影响分类概率或神经元的像素
- 要考察像素对分类概率的影响,我们可以考虑概率对于此像素的导数。这样,只需单次反向传播我们就可以得到梯度的 Saliency Map 。3这将有助于检查 CNN 是否学习到了我们所希望的部分,例如其分辨船的办法不是找水而是找船本身。一个有趣的延申是,我们可以试着用 Saliency Map 来做无监督的图像语义分割,但这个做法在广泛的输入上的表现并不一定好。
- 如果希望考察像素对于某一中间神经元的作用,我们当然也可以考虑反向传播。但实践中这样做的效果并不好。有研究提出了一种奇妙的技巧4,称作 Guided Back Propagation ,也就是,原先的反向传播是把梯度矩阵中正向传播时小于 0 的位置的值全部改成 0 ,而导向反向传播则还要对梯度矩阵再做一次 ReLU 。这种技巧似乎可以较好的改善 Saliency Map 。
图像生成
- 严格的说并不算是生成,而是 CNN 结构可视化的有趣应用。
根据特征生成图像与 Deep Dream
给定已经训练完成的 CNN ,我们希望生成最符合其提取出的某个特征的图像。最简单的情况是,考虑某一类分类概率、或是某一个神经元的值,我们希望从随机矩阵开始,使用 (Guided) Back Propagation 与梯度上升生成最大化该指标的图像。为了使得图像看起来更好,我们同样需要为优化目标加上正则化,例如图像的
范数。值得一提的是,通过某些精心设计的正则化,我们可以生成出看起来很不错的图片。 另一方面,优化对象也可以是 feature map 或者 feature vector 之类的,这种思路称作 feature inversion 。简单的说,我们希望可以找到一个图像最好的匹配了给定的 feature vector ,当然也需要带上某种正则化。度量匹配程度的方式一般是
范数,正则化则考虑优化图像的平滑度。值得一提的是,这样优化出的结果往往与原先输入的图像匹配的相当好。而且 feature vector 的深度越浅,匹配越好;深层的 feature vector 会倾向于丢失图像的局部颜色与线条,而保留整体结构。 
另一个有趣的应用是 Deep Dream 。简单的说,我们将输入图像通过 CNN ,将选定层的计算结果直接作为该层的梯度进行反向传播。这样做的结果是,以“令该层的特征最为显著”为目标进行优化。5这样做会把 CNN 中该层保存的特征强加到原图中,很可能会优化出一些阴间结果,取决于原先 CNN 训练的数据集里有什么。6

Texture Synthesis 与风格迁移
Texture Synthesis 指的是,给定材质模板,我们希望基于此模板合成更大的图片。这意味着,我们希望学习材质的颜色、线条等特征,而丢弃其空间特征。有趣的是,这恰好可以用 CNN 的 feature map 的 gram matrix 来描述。简单的说,对于一层的 C*H*W 的 feature map ,其一共有 H*W 个 feature vector ,取其两两做外积7,并取均值得到 C*C 的 gram matrix 。如上得到的 gram matrix 描述了 feature vector 的未归一化的协方差,可以认为其描述了这一层的抛开空间关系的特征。8
而使用 gram matrix 做 Texture Synthesis 的方法则是,令材质通过 CNN 以提取特征,取其前若干层的 gram matrix ,再令噪声输入通过 CNN ,同样得到其 gram matrix ,再以所有 gram matrix 的相似度9为目标进行优化。
如果把艺术作品作为材质,我们就可以做风格迁移了。简单的说,Texture Synthesis 是保留局部而舍弃整体,而深层的 feature inversion 则是保留整体而舍弃局部。所以我们考虑同时对 gram matrix 和 feature vector 做优化10,这样就可以把前者的局部特征添加到后者的整体框架上。令人意外的是,这样做的结果相当好。
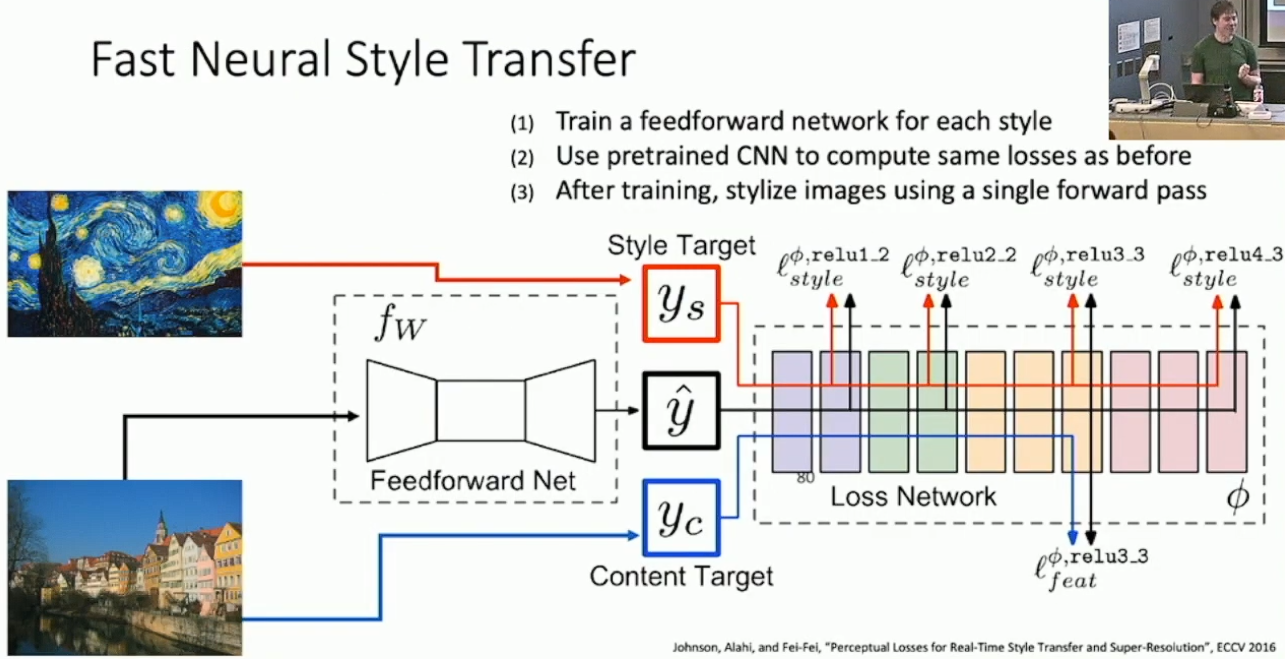
一个问题是每一次风格迁移都要做梯度上升的话就太慢了。解决方案是训练一个前馈网络来做风格迁移,而把后面的 CNN 整体当作损失函数。
另外还有一些细节,例如使用 instance normalization 来加速收敛和使用 conditional instance normalization 来利用同一前馈网络同时做多种风格转换和风格混合,这里就不深入了。
向量之间的夹角。↩︎
我们只关注神经元的视野,其余无关的像素点是不考虑的。↩︎
这篇论文里有一些很好的可视化。Simonyan, Vedaldi, and Zisserman, Deep Inside Convolutional Networks: Visualizing Image Classification Models and Saliency Map, ICLR Workshop 2014.↩︎
截止2019年,这种技巧似乎并没有一个好的理论解释。↩︎
目标函数为该层的 feature map 的
范数之和。↩︎ 如果你在 ImageNet 上训练,可能会得到 dog fish, admiral dog, dog frog 之类的。↩︎
其实就是做矩乘得到 C*C 的结果。↩︎
其实这些东西我也不是很熟。这里是口胡的。↩︎
一般是
范数的加权和。↩︎ 大概是对两者的损失函数做加权和。↩︎
- 标题: 卷积神经网络的可视化与可解释性
- 作者: RPChe_
- 创建于 : 2025-03-21 00:00:00
- 更新于 : 2025-03-22 01:02:44
- 链接: https://rpche-6626.github.io/2025/03/21/DL/CNNapp/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。

