循环神经网络
我本来还以为 RNN 会更厉害一点来着。
问题背景
原先的问题(Image Classification)是 one to one 的,即接受一个输入,并只有单一输出。为此,我们设计了 feed forward 的神经网络。而有时我们需要处理其它类型的问题,例如:
- one to many: Image Captioning.
- many to one: Video Classification.
- many to many: Machine Translation.
总的来说,在这些问题中,我们需要处理序列输入/输出,而这时,典型的前馈神经网络就不那么好用了1。为了处理序列问题,不妨考虑引入类似于递归的机制,循环的利用网络,并基于上一步的信息和当前的输入进行下一状态的计算,这样就得到了 Recurrent Neural Network 。
算法描述
具体的,用
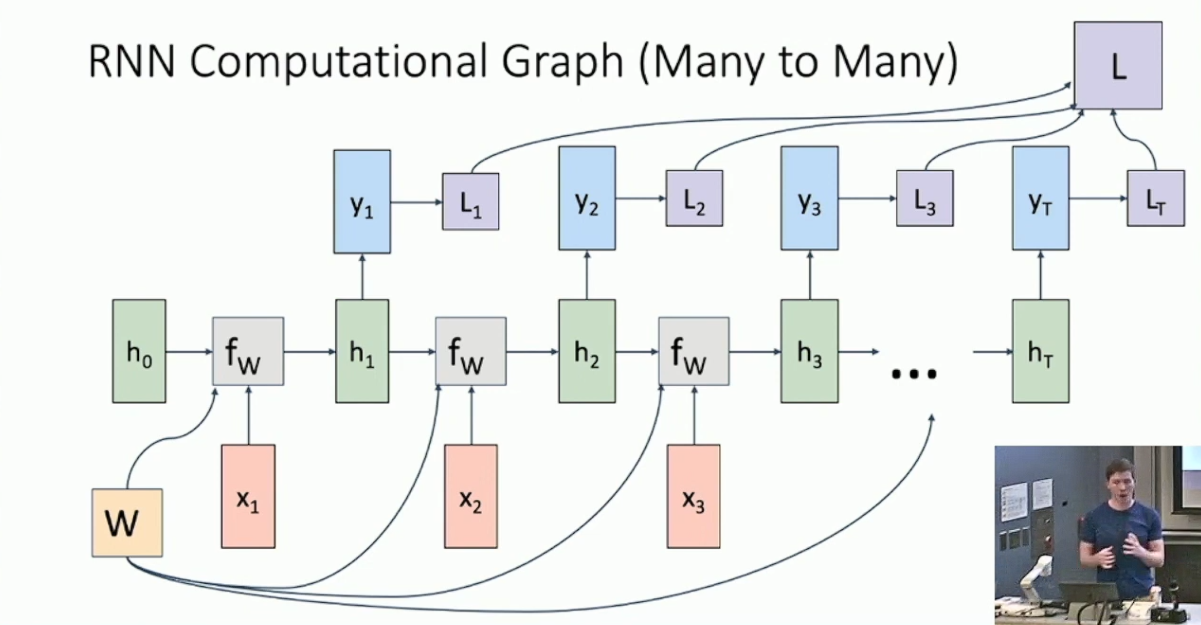
表示步数,我们希望引入一个 hidden vector(记作 )来保存 RNN 的状态,并利用某个固定的函数 基于上一步的状态 和当前输入 来计算当前状态 : 最朴素的选择(称作 Vanilla RNN)是2: 而如果这一步还需要输出,就基于当前状态计算得到输出 。Vanilla RNN 的实现是: 下图展示了一个 many to many 的 RNN 的结构:3 
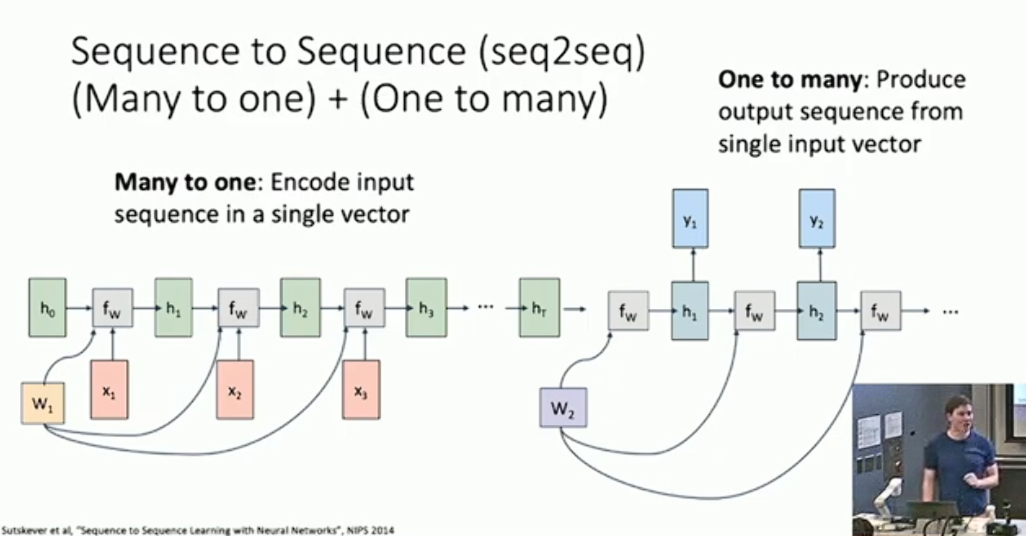
注意到训练 RNN 时每一个输出都需要有损失函数,而总共的损失函数则是它们的和。RNN 的设计比较灵活,每一步都可能有输入或输出、或两者皆有。但其大体的设计与上图差别不大,这里就不赘述了。有一类比较的特别的 many to many 问题,需要我们将输入和输出分离4,那么我们就相应的拼接两个 RNN :
Justin 接下来举了一个比较简单的例子,即一个用于 Language Modeling 的 many to many 模型,其实就是基于给定的语料预测下一个字母。一个有趣的细节是,这个任务每一步的输入是一个大小为字符集的 one hot vector ,所以在做矩阵乘法时其等价于选取矩阵的一列。这样做看起来表达能力并不强,所以我们可以在计算 hidden vector 前加入一个 embedding layer ,即先做 一次矩阵乘法。这样做其实等价于用一个“嵌入向量”来表达字符。5
RNN 的反向传播
- RNN 的反向传播会多次经过自身6,这在计算上没什么问题,但是由于显存大小有限,整个 RNN 的 Computational Graph 可能会存不下。所以我们需要采取一个折衷的办法,称作 Truncated Back Propagation through time ,即,我们选择一个块长 B ,每处理 B 步,我们就对这 B 步的结果做一次 Back Propagation ,并更新 Weight Matrix ,再使用更新的结构参与以后的处理。
Hidden Vector 的可解释性
- 现在我们考察 Hidden Vector 是否具备可解释性。不妨考虑 Hidden Vector
的每一维是不是捕捉到了某种信息。还是以 Language Modeling 为例,有研究7使用 RNN 建模了某些语料库,跟踪了
Hidden Vector 的某些维度在预测输出时的活跃程度,发现这些维度捕捉了包括
for循环、引用、换行符在内的某些有趣的信息。这说明 RNN 的 hidden state 的确概括了这些特征,学到了语料库中的某些特殊结构。
LSTM
Vanilla RNN 的梯度流其实有很大的问题。我们知道在 0 附近
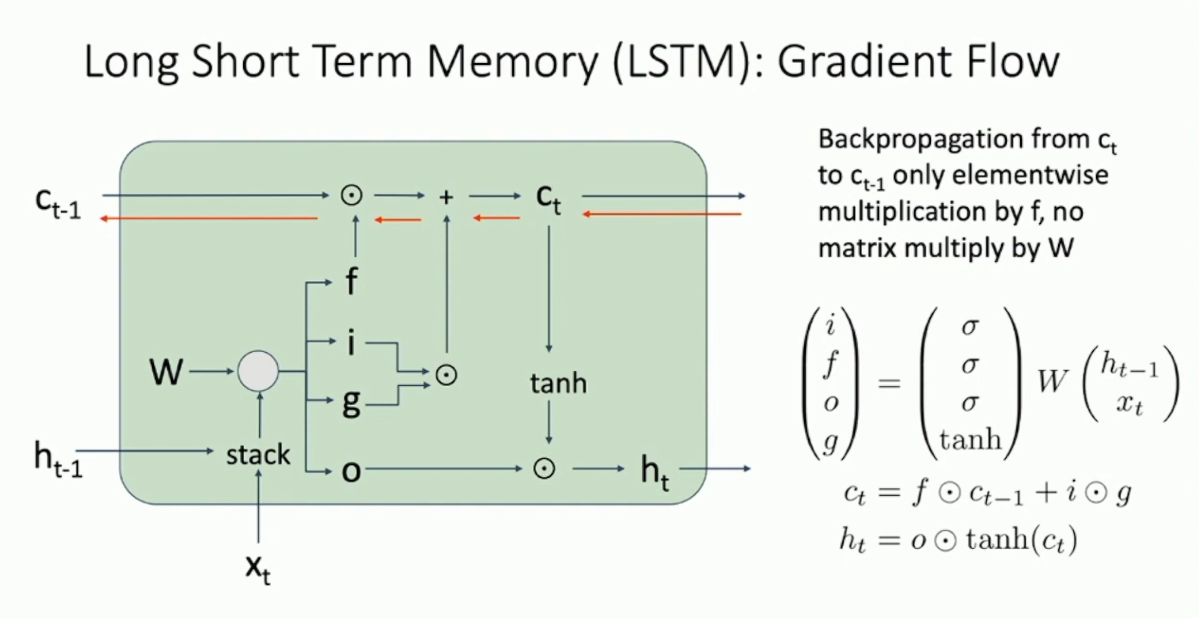
表现为恒等映射,所以在反向传播的时候 hidden vector 的梯度会包含很多 的幂,这一点在处理长序列时尤为明显。所以 hidden vector 的梯度很容易爆炸或者消失。为此,我们考虑修改 RNN 的结构。一个经典的方式是使用所谓的 Long Short Term Memory 。其形式如下: 简单的说,我们用分块矩阵将 Vanilla RNN 中的形式写成单次矩阵乘法,并将得到的向量的维数扩大为原先的四倍,将其切分成 4 个部分,分别通过 sigmoid 或 tanh 得到四个向量,称作 input gate 、forget gate 、output gate 和 gate gate8 。我们将要多维护一个中间结果 cell stat(记作 ,意义是 LSTM 的内部的隐藏状态),并按照以上的形式计算得到新的状态,其中 指得到向量的 element-wise product 。这样做的意义是,我们以 作为核心,而 都是 0 到 1 间的实数,它们表示了“程度”。具体的, 表示了当前我们希望往 里面写什么,而 表示每一维要写多少、 表示要“遗忘”多少以前的状态。最后再用 通过 ,得到我们要输出什么,再乘上 ,代表每一维要输出多少。 以上所述均是 intuition ,LSTM 要解决的主要问题其实是为梯度提供顺畅传播的通道。不妨考虑 LSTM 的 Computational Graph :
可以看到 cell state 反向传播的通道并不会经过任何的非线性计算,而只是和
做逐点乘法而已,这对于反向传播是非常友好的。当然,鉴于 的值处在 0~1 之间,这样设计可能还是会导致梯度消失。无论如何,这的确大大改善了 Vanilla RNN 。
Muti-layer RNN
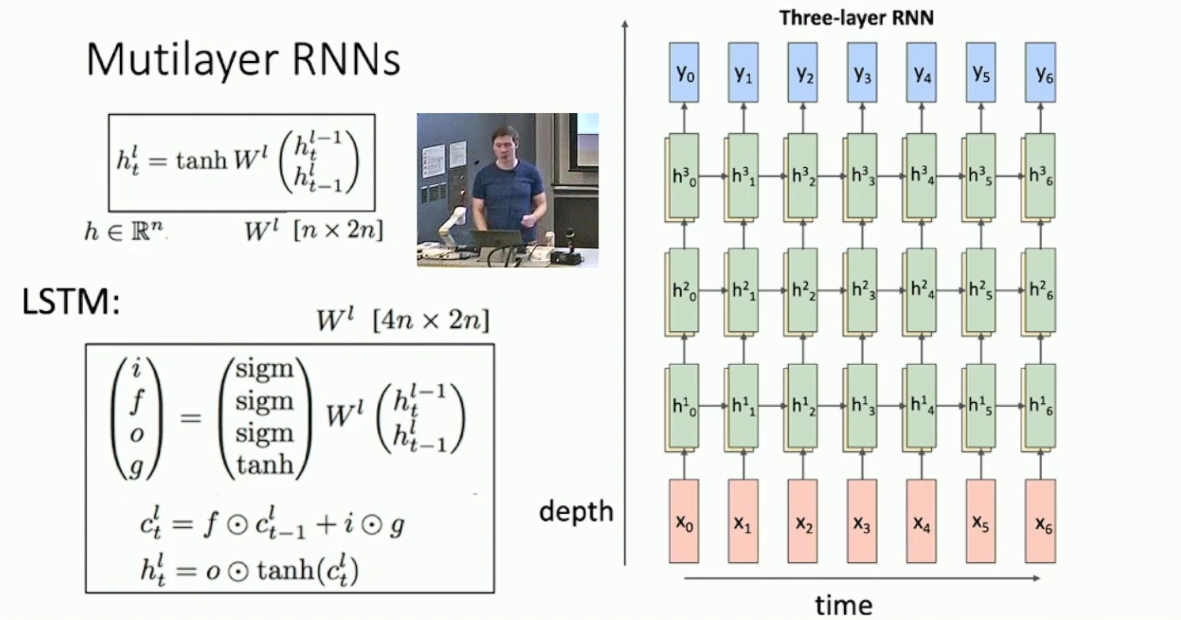
当然我们也可以像 CNN 那样增加 RNN 的深度,大体结构如下图所示:
我们可以期待增加一定的层数,例如 3 到 5 层,会改善 RNN 的表现。但 RNN 一般不会像 CNN 那样搭建非常深的网络。9
RNN 的其它结构
- RNN 其实有很多其它结构,例如 Gated Recurrent Unit10 之类的,此外还有自动生成 RNN 模型的研究11。但大体看来它们似乎并没有得到显著优于 LSTM 的结果,所以我们也就不深入了。
指先前的前馈网络。毕竟 transformer 也是前馈的。其中“前馈”指信息总是向前传播。↩︎
简洁起见,下面省掉了 bias term ,但实际实现中当然是有的。↩︎
可能的任务场景是 Video per-frame Classification 。↩︎
例如 Machine Translation 。RNN 需要先理解整个句子才能翻译。↩︎
这看起来是一个非常简单的模型,但是你如果喂给它数据,它竟然真的能吐出像模像样的结果。↩︎
称作 Back Propagation through time 。↩︎
Karpathy, Johnson, and Fei-Fei: Visualizing and Understanding Recurrent Networks, ICLR Workshop 2016.↩︎
我不知道这个到底应该叫什么名字。↩︎
不知道具体为什么。可能是因为算力限制或者效果不好吧。↩︎
Cho et al, Learning phrase representations using RNN encoder-decoder for statistical machine translation, 2014.↩︎
Zoph and Le, Neural Architecture Search with Reinforcement Learning, ICLR 2017.↩︎
- 标题: 循环神经网络
- 作者: RPChe_
- 创建于 : 2025-03-18 00:00:00
- 更新于 : 2025-10-11 17:54:45
- 链接: https://rpche-6626.github.io/2025/03/18/DL/RNN/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
