卷积神经网络的发展
本文梳理了 CNN 模型的发展,简要介绍了 AlexNet 、VGG Net 、Google Net 以及 ResNet 。
ImageNet
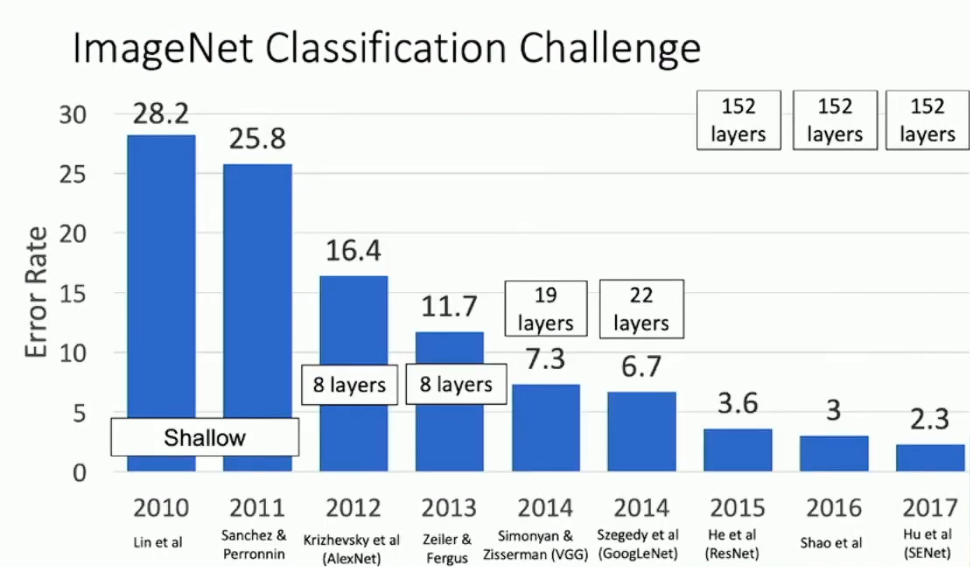
ImageNet Challenge(简称 ILSVRC)是图像识别领域的著名赛事,于 2010 年启动,后来在 2017 年被 CNN 终结了。ILSVRC 使用的数据集是 ImageNet 的子集,包括 1000 个类别、约 120 万张训练图像、5 万张验证图像与 10 万张测试图像,输入模型的图像格式均为 3 channels 224*224 pixels 。我们将介绍 ImageNet 历年最成功、最有代表性的 CNN 模型。

AlexNet
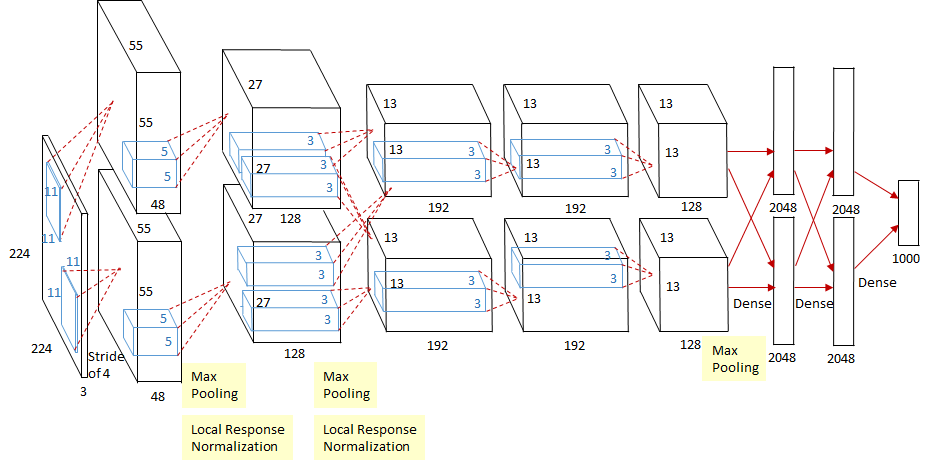
在 2012 年以前的图像识别领域,CNN 尚且不是主流,直到当年 AlexNet 取得了重大突破。以下是 AlexNet 的结构:
如上图所示,AlexNet 由 5 个卷积层加上若干池化层再加上最后的三个全连接层构成。这个结构看起来比较奇怪,主要是因为受当时的算力限制,AlexNet 是在两块 GTX580 上分别训练的。此外 AlexNet 也用到了一些被后来被弃用的技术,例如 Local response normalization ,我们也不会再谈。
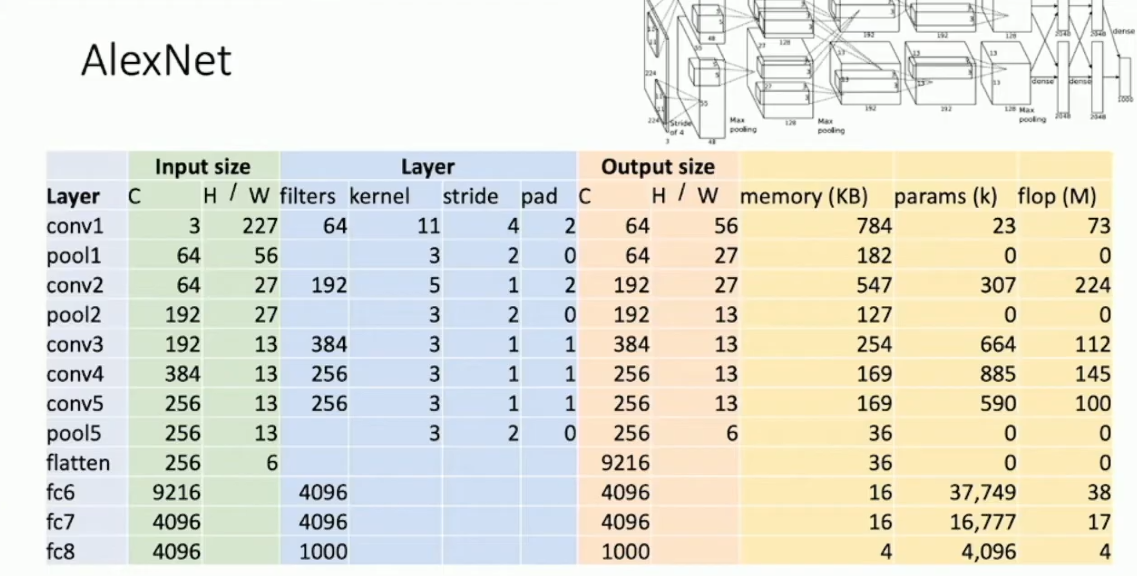
衡量模型表现的重要因素,除开准确率之外,还有内存占用(memory)、参数量(params)以及浮点运算量(flop)。按照上篇中我们谈过的 CNN 的结构,这些指标都不难计算。下表给出了 AlexNet 的详细指标:
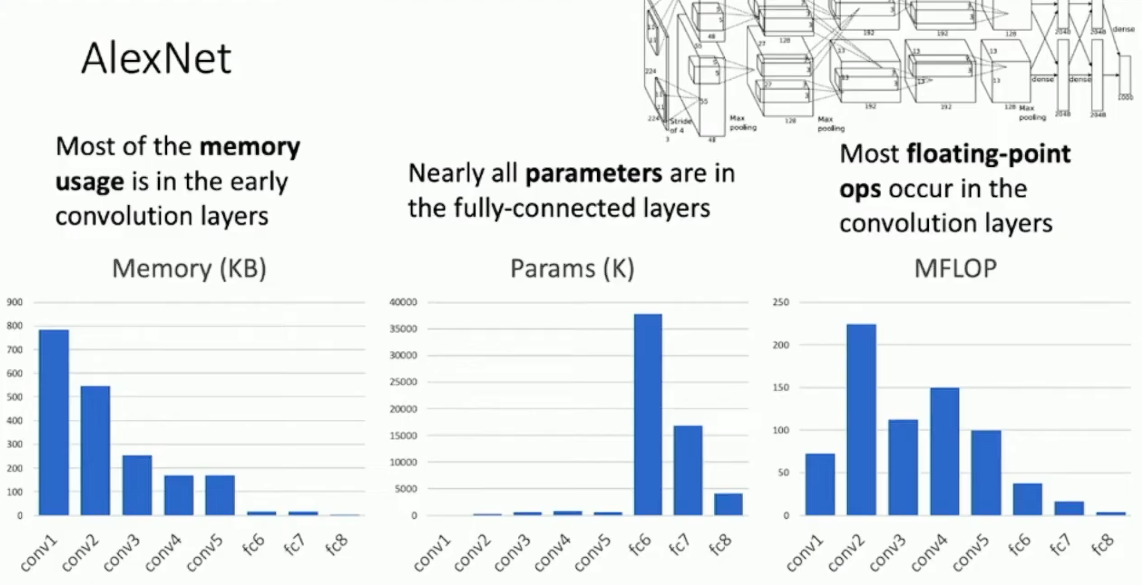
下图是 AlexNet 各层开销的柱状图,并略去了开销极小的池化层:
可以看到计算开销和空间开销主要来自卷积层,而参数量则主要来自全连接层。
VGG Net
2013 年的 ZF Net 基本是一个大号的 AlexNet ,所以我们就略去不讲。而 2014 年则同时有两个模型取得了相近的优异表现,而且各自的实现思路有较大不同,其一是 VGG Net 。1
AlexNet 的一个缺点是超参数太多,这使得模型调参非常麻烦。而 VGG Net 的主要目标之一便是寻求一个更好的构建网络的范式。首先,注意到 5*5 卷积所达成的视野可以被两次 3*3 的卷积替代,并且后者的计算量与参数量更小,还提供了更多的非线性化,这暗示了单次大尺寸卷积的效果也许是不如多次小尺寸卷积的2。所以,VGG Net 提供的解决方案是,只做 3*3 卷积。具体的,VGG Net 的思路是构造某种网络阶段,例如两次 3*3 stride 1 pad 1 的卷积再加上一次 2*2 stride 2 的 max pool ,通过堆叠网络阶段来搭建网络,并在每一层 pooling layer 后倍增 channel 数,如下图所示:
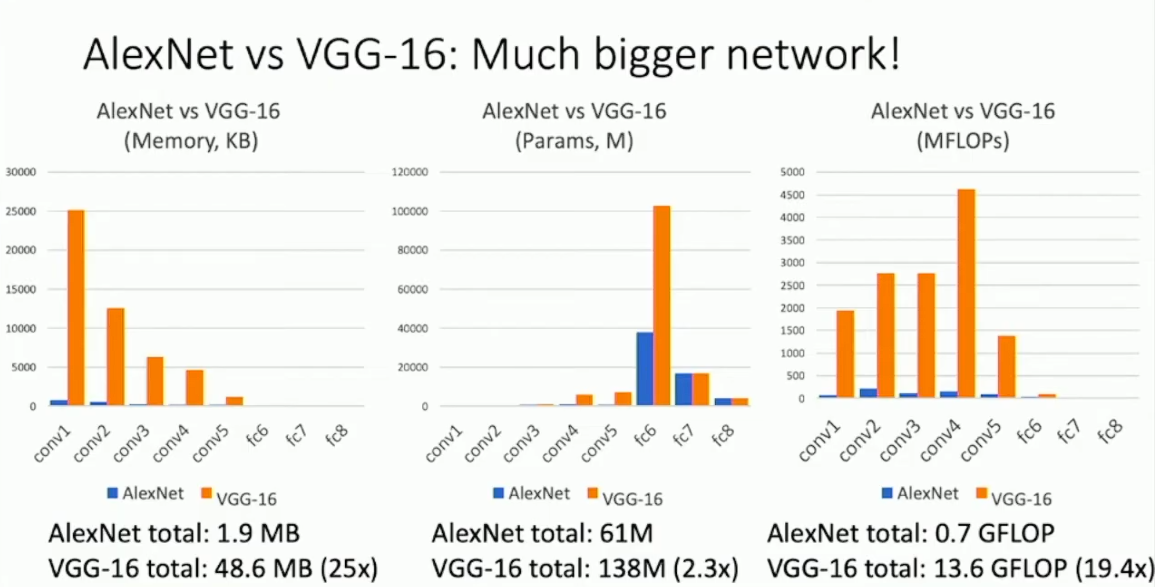
同 AlexNet 比较 VGG Net 的各项指标:
VGG Net 的算力消耗激增。实际上,VGG Net 也是我们所要介绍的算力开销最大的模型。

Google Net
2014 年脱颖而出的另一模型则是 Google Net 。Google Net 与 VGG Net 有很多共同点,但特别之处是 Google Net 把重心放到了控制模型的算力开销上。Google Net 在模型的最初几层采取了激进的 down sample 策略以减少后续计算量。
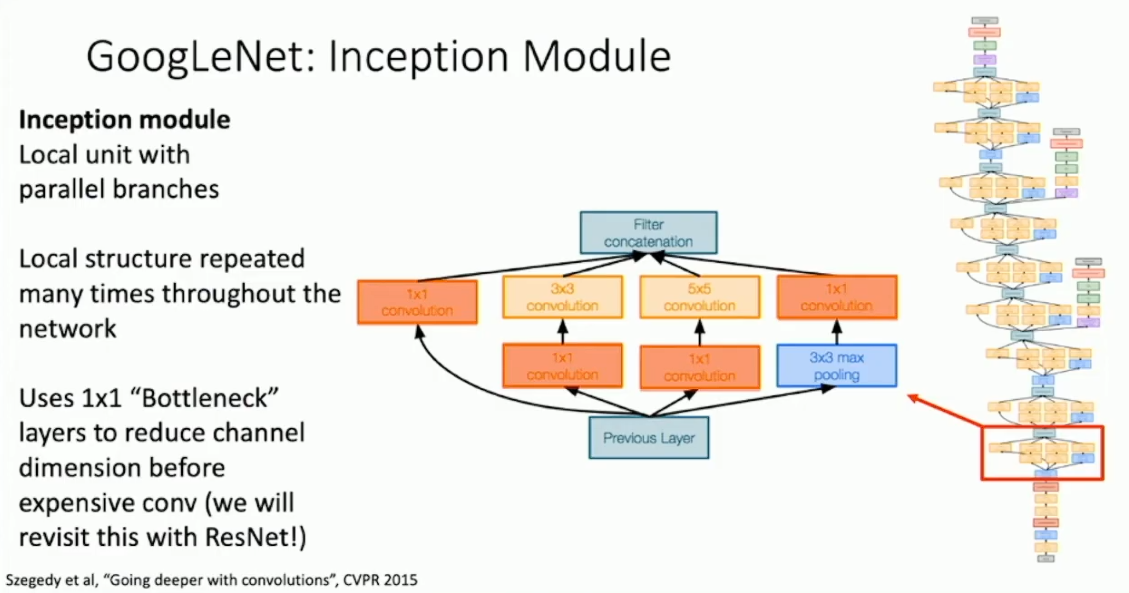
不同于 VGG Net ,Google Net 采用了复用网络模块的思路,即通过构造一个通用模块,再不断堆叠来搭建网络。Google Net 在网络模块中引入了平行分支,通过在不同的分支中同时做不同尺寸的卷积来避免引入卷积尺寸这一超参数。而为了控制卷积层的时间开销,Google Net 选择在卷积层之前加入 1*1 卷积层(称作 bottlenecks)来缩减 channel 的数目。
Google Net 的另一个创新是,通过 global average pooling 来替代原先模型最后巨大的全连接层,从而缩减参数量。具体的,Google Net 最后得到了 7*7*1024 的 tensor ,然后其通过 global average pooling 消除了 feature map ,只留下了一个 feature vector ,再使用单个全连接层来转换得到最后的 1000 个分类指标。
Google Net 在中间加入了一些额外的输出分支,称作 Auxiliary Classifiers ,这看起来很奇怪。实际上 Auxiliary Classifiers 的用处并非预测,而是通过在中途注入梯度来加速模型收敛,而这种技巧在后来的模型中被弃用了。

ResNet
2015 年是非常重要的一年,这一年诞生了很多在深度神经网络中至关重要的技术,例如 Batch Normalization 和 Residual Block ,这使得我们可以搭建深度远超以往的神经网络,即 ResNet 。
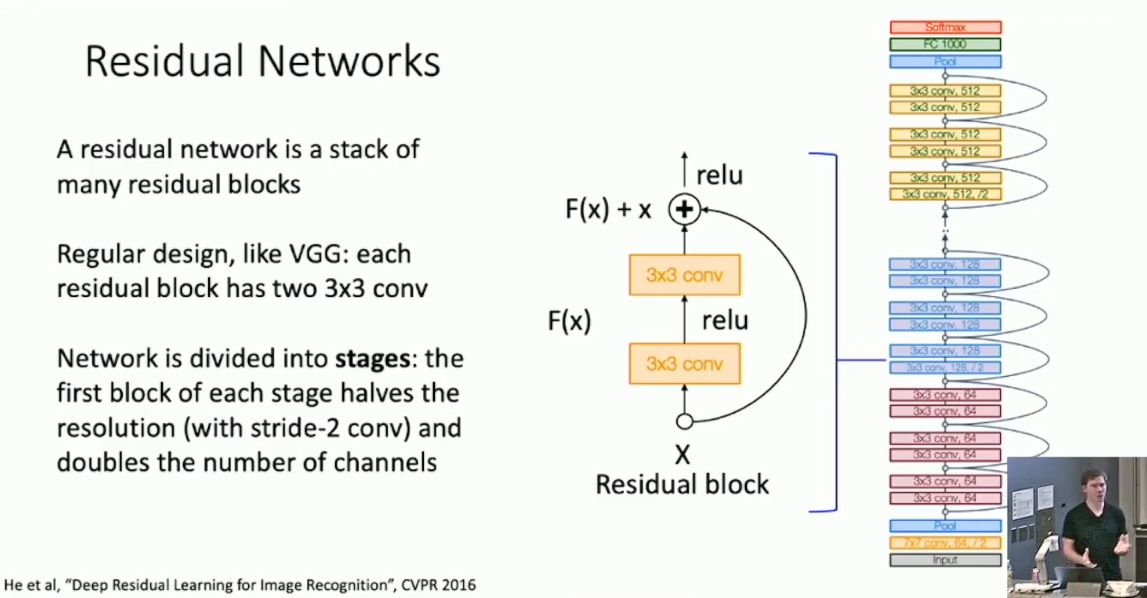
搭建深度网络的主要阻碍之一,就是随着深度的增加,收敛也愈发困难,这个问题在 Google Net 上已经初露端倪。而通过我们先前介绍的 Batch Normalization ,即使不依靠 Auxiliary Classifiers ,Google Net 也可以较好的收敛,但这还不够好。不妨想想为什么深度网络的预测效果反而不如更浅的网络:理论上我们只需抽调出深度网络特定的几层,使其模仿浅网络就好了,而其余的层只需被设为恒等映射即可。所以我们猜测深度网络效果不好的原因可能是卷积层学习恒等映射的效果不好。要针对这一点改进,我们考虑对原先的网络模块(称作 plain block)加入一条直接传递当前结果的捷径,修改为如下的 Residual Block :
我们可以在 ResNet 中找到很多 VGG Net 和 Google Net 的影子,例如其采取了类似 VGG Net 的阶段化思想,并学习 Google Net 在最开始进行激进的 down sample 来降低后续开销,以及在最后安排 Global Average Pooling Layer 而非巨大的 Fully Connected Layer 。此外,在深层网络中,ResNet 采取了另一种设计来替代以上的 Residual Block(称作 Basic Block),即在单个 Block 内只做单次 3*3 卷积,而在之前之后分别插入 bottleneck 来控制 channel 的数目,以缩减计算开销,同时增加深度和非线性计算数,称作 bottleneck block 。
以上的机制组合在一起,使得 ResNet 保持了每层较低的时间开销,以及更快的收敛速度,从而可以搭建深度远超以往的网络,实现跨越式的性能增长。而 ResNet 也确实横扫了 2015 年 CV 领域的各大竞赛,几乎终结了 ILSVRC 。
后续改进
- 后续的改进大部分都是基于 ResNet 的,例如 "Pre-Activation ResNet Block" 、ResNeXt 、Densely Connected Neural Network 。但实际上 ResNet 在准确性这方面的改进空间已经不大了,所以研究者开始把重心转移到别的方面,例如缩减算力开销(MobileNets),或是研究自动生成深度网络模型的模型。以后我们不会再详谈这些方面,而是把 ResNet 作为 Image Classification 的最终方案,然后介绍 CV 领域的其它问题。
- 最后 Justin 给了一些建议,比如一般不要去试着搭建自己的网络,而是优先考虑已有的方案,因为一般院所的算力资源都是相当有限的。
- 标题: 卷积神经网络的发展
- 作者: RPChe_
- 创建于 : 2025-03-07 00:00:00
- 更新于 : 2025-10-11 17:54:11
- 链接: https://rpche-6626.github.io/2025/03/07/DL/CNNdev/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。

