
卷积神经网络
这应该是目前最强大的处理图像识别问题的工具。
问题背景
- 给定包含图像的训练集与测试集,请基于训练集中标注的分类结果对测试集中的图像进行分类。
算法描述
不妨先考虑一下 Fully Connected Neural Network 的缺点是什么。首先,FCNN 的计算复杂度太高了,每一次我们都要做全连接层的计算;其次,FCNN 将图像展平成了向量,这摧毁了图像的空间结构。而为了改进这两个问题,我们将要引入著名的 Convolutional Neural Network ,即 CNN 。
最经典的 CNN 主要包含了两个部分,分别被称作 Convolutional Layers(卷积层)与 Pooling Layers(池化层),在 CNN 的最后往往也会加入少量的 Fully Connected Layers(全连接层)。后来的研究为 CNN 引入了 Batch Normalization 这一技术,而其现在也已经成为了 CNN 的重要组成部分。
Convolutional Layers
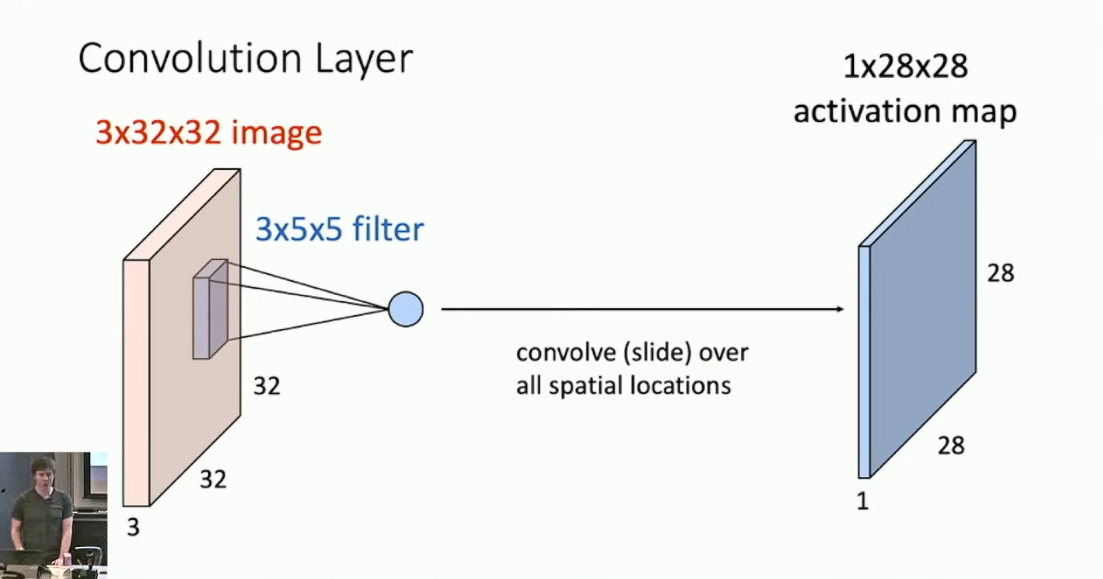
Convolutional Layers 的主要思路是,通过某种方式来保存图像的 2D 空间结构。举例而言,假设我们的输入是 3 channels 32*32 pixels 的图片,卷积层由 6 个 filter 构成,每个 filter 都是 3*5*5 的矩阵,单个 filter 用于给图片的所有 5*5 的部分采样,采用
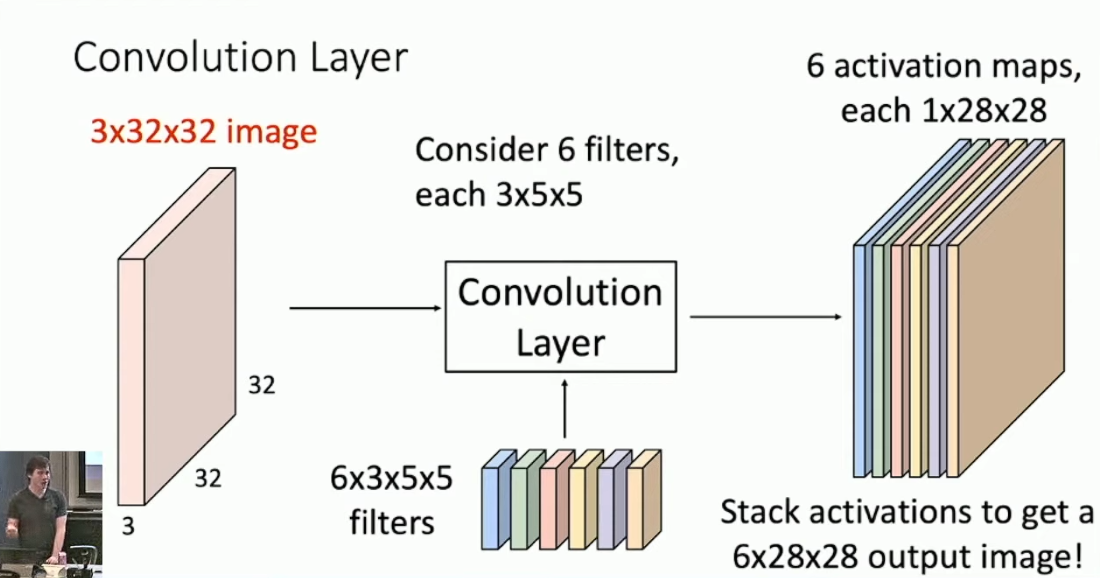
内积。特别的,我们要求每个 filter 的 channel 数目和原图像的 channel 数目一致,而 filter 的长宽大小则是可以调整的。那么通过每一个 filter 我们都可以对原图采样得到一个新的矩阵,称作 feature map 。 
对所有的 6 个 filter 分别采样,我们就得到了 6 张 feature map ,这就是 Convolutional Layer 的输出。
特别的,我们也可以考虑所有的 28*28 个位置,每个位置都有一个 6 维向量,我们将其称作 feature vector 。而每个 filter 往往也会带有一个常数,我们将它们整体称作 bias vector 。在卷积层之后我们一般也会加入激活函数,例如 ReLU 。
想想卷积层做了什么。在 FCNN 中,我们可以认为 hidden layer 是在学习 template ,即图像的模板;而在 CNN 中,convolutional layer 的工作更像是学习 feature ,即图像的特征。这样,我们就将学习对象从整体变成了局部。
Convolutional layer 还有一些技术细节。首先,可以发现每一层 convolutional layer 都会导致图像的尺寸减小,这限制了网络的深度。而解决方案则是做 padding ,一般来说是在网络的四周补 0 。最常见的操作是 same padding ,即使得 padding 以后得到的 feature map 和输入量具备相同的尺寸1。另一个细节则是,通过连续的 Convolutional layer ,feature map 中的每一个点都对应了原先的一个较大的部分,即保存了这个局部的特征。如果我们希望尽快建立 feature vector 对于全局的印象,或者快速缩减 feature map 的大小,可以考虑引入 stride ,即每次都间隔一定步数再做取样。方便起见,我们一般会设置 stride 的大小使其恰好可以覆盖全图。将输入量的边长2记作 W ,Filter 的边长记作 K ,Padding 大小记作 P ,Stride 大小记作 S ,那么输出的 feature map 的边长就是 (W - K + 2P) / S + 1 。
Pooling Layers
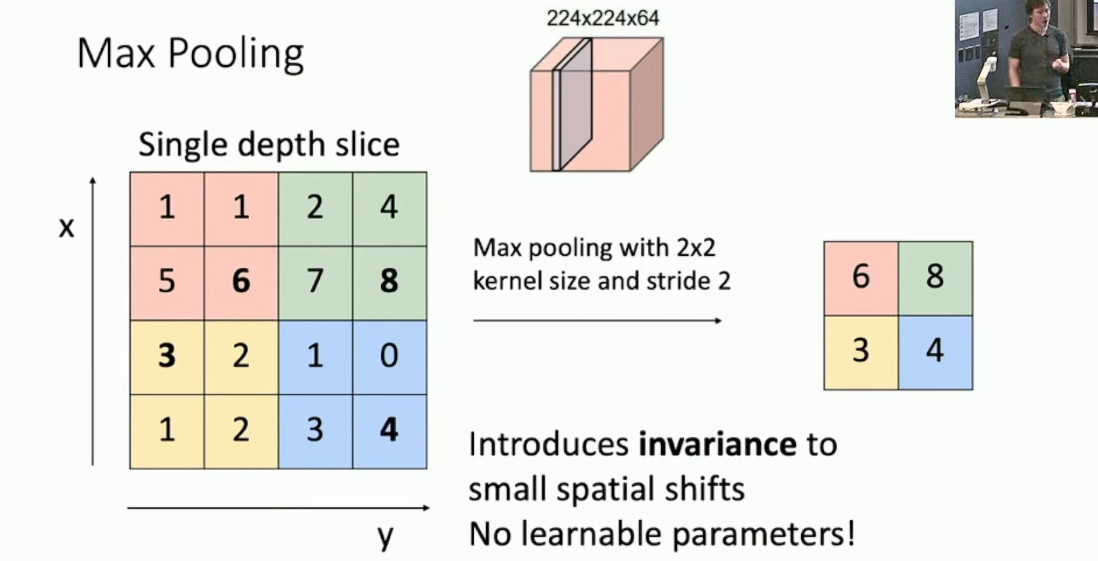
Pooling Layers 的主要作用是快速对输入量做下采样(down sample),即降低输入量的大小。比方说 64*224*224 的输入量通过 pooling layer ,就被 down sample 到了 64*112*112 。Pooling Layer 有两个参数 Kernel Size 和 Stride ,还有用于采样的 Pooling function ,一般是取 max 或者取 mean 。具体的,Pooling Layer 会使用 Pooling function 对输入量的每一个 feature map 的边长为 Kernel Size 的部分做步长为 Stride 的采样。一般来说我们会设置 Kernel Size = Stride ,即将 feature map 切分为多个边长恰为 Kernel Size 的小块。
Batch Normalization
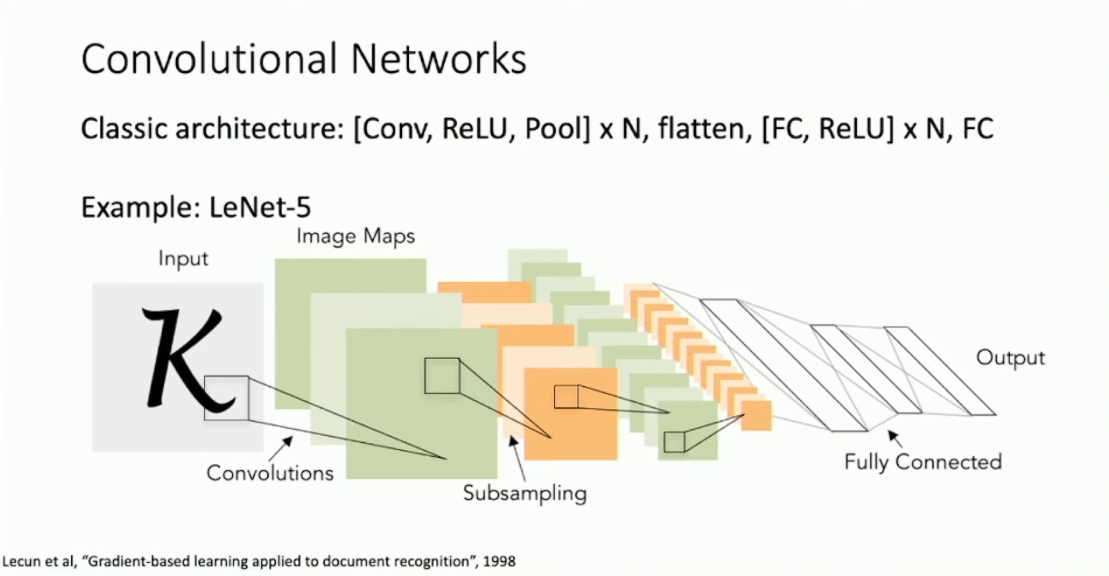
通过 Convolutional Layer 、Pooling Layer 以及 Fully Connected Layer ,我们就可以搭建出完整的 CNN 模型了。下图展示了经典的 Lecun 搭建的 CNN 模型 LeNet-53 :
但有一个棘手的问题是,随着网络的深度不断加深,使其收敛变得非常困难。4相对比较近的工作提出了一个技巧,即所谓的 Batch Normalization 。不妨想想深度网络难以收敛的潜在原因:我们的优化方式是基于梯度的,那么对于单一变量,其偏导等价于固定其余所有变量的取值,然后选择这个变量下降最快的方向。在迭代的过程当中,所有变量会同时更新,导致不同层的变量之间的变动缺乏联系。从而为了避免损失函数的剧烈震荡,学习率就必须足够小,导致了收敛速度慢。5
具体的,为了辅助收敛,我们希望神经网络中的每一层所接受的分布6满足比较好的性质,因此针对每一个 channel ,我们要求训练集上所有数据的 feature map 的分布满足期望为 0 且方差为 1 。下图是对 Fully Connected Layer 做 Batch Normalization 的演示:
但是显然实际上 feature map 的分布不一定是满足这个要求的,所以我们还要对于每一个 channel 加入两个可学习的参数
和 ,分别为 feature map 的常数因子和常数偏置。反映到上图的例子上就是引入 ,使得最后的结果 。 但是 Batch Normalization 还有一个很大的问题,就是其导致网络的预测与输入的 Batch 相关,这显然是很荒唐的。我们的解决方案是,在训练完成后固定期望
和方差 。至于它们的取值,要么就在训练的时候维护历史指数均值,要么就直接取最后几轮训练的结果的均值。 但这样做了以后又会引入一个问题,就是我们的模型在预训练阶段和预测阶段所做的事情其实是不一样的,而我们期待训练和预测时模型的动作应该是相同的。7对此,我们考虑更换 Normalization 的方式。可选的方案是 Layer Normalization(对每层内部做 Normalization)或 Instance Normalization(对每个 feature map 做 Normalization)。

这里的尺寸是不管 channel 的。↩︎
方便起见,我们令输入的图像为正方形,每一次处理的时候我们也保证得到正方形。↩︎
Lynette↩︎
Lecun 在 1998 年发表了这个模型,而当时其实还没有遇到这个问题,因为其时的网络还是很浅的。我们在下篇会讲 CNN 的发展,那时再详谈这个问题。↩︎
这只是一个直观上的解释。截止到 2019 年,Batch Normalization 的有效性的理论保证似乎还是 Open Problem 。因此以下对 Batch Normalization 的描述其实也都仅是直观上的。↩︎
这里的分布是指训练集上的 feature map 的分布。↩︎
Justin 说可能会导致一些问题。↩︎
- 标题: 卷积神经网络
- 作者: RPChe_
- 创建于 : 2025-03-07 00:00:00
- 更新于 : 2025-04-12 16:17:35
- 链接: https://rpche-6626.github.io/2025/03/07/DL/CNN/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
